1. Überblick
PostProc 2 ist ein Programm zur Analyse und Nachbearbeitung (engl. post-processing) von zeitabhängigen Daten, wie sie in dynamischen Simulationsprogrammen entstehen (z.B. DELPHIN, THERAKLES, NANDRAD, MASTERSIM, und beliebigen anderen Simulationsprogrammen). Es ist auch gut geeignet für die Analyse von Messwerten und experimentellen Daten. PostProc 2 setzt daher zwingend einen Zeitbezug im Datensatz voraus (siehe dazu Datenformate/Datentypen), und bei den meisten Diagrammen ist die X-Achse die Zeitachse.
Bei Daten mit zusätzlichem Koordinatenbezug (z.B. Feldausgaben), kann man natürlich auch nur die Daten eines einzelnen Zeitpunkts darstellen, z.B. in Farbverlaufsdiagrammen. In diesem Fall ist die X-Achse immer eine Koordinatenachse, und ggfs. die Y-Achse ebenfalls.
1.1. Funktionsübersicht
Das PostProzessing ermöglicht:
-
Import von Daten in unterschiedlichen Eingangsdatenformaten
-
Datendarstellung, hereinzoomen, Einheitenumrechnung, linear/log-Skalen für die Achsen, …
-
flexible und schnelle Diagrammformatierung und Export in Vektor- oder Bitmapgrafiken (mit präzisen Größen- und Skalierungseinstellungen für korrekte Druckdarstellung)
-
Analyse und Transformation der Daten mit Modellen
-
Berechnungen mit Datensätzen
-
Aktualisierung der Ansicht/Diagramme bei Änderung der Quelldaten ohne Verlust der Formatierung (Live-Ansicht der Ergebnisse, während die Simulation noch läuft)
1.1.1. Besonderheiten und nette Funktionen
Eine wesentliche Eigenschaft von PostProc 2 ist die Trennung von Daten und deren Visualisierung. Sie erlaubt die Aktualisierung von Daten/Dateien und damit auch eine Live-Ansicht der Berechnungsergebnisse (siehe Abschnitt Datenaktualisierung).
In einer Sitzung (so etwas wie einer Projektdatei) werden verschiedene Diagrammkonfigurationen gespeichert. Die Sitzungsdatei mit Endung .p2 ist selbst eine XML-Datei und kann daher auch einfach im Texteditor bearbeitet werden. Auch kann man einfach Diagrammkonfigurationen im Texteditor vervielfältigen, oder durch Suchen-und-Ersetzen Änderungen an mehreren Stellen durchführen. Man könnte Sitzungsdateien auch über ein Skript automatisiert erstellen und anpassen.
Die eigentlichen Daten werden nicht in der Sitzungsdatei gespeichert, sondern in externen Dateien referenziert. Dadurch können letztere einfach aktualisiert werden und PostProc 2 wird beim Lesen/Aktualisieren der Sitzungsdatei einfach die neuen Daten anzeigen. Sehr praktisch!
|
Sitzungsdateien lassen sich als XML-Dateien im ASCII-Format gut in Versionskontrollsystemen verwenden. |
Der Diagrammexport kann auch automatisch über einen Kommandozeilenbefehl ausgeführt werden. Damit ist es möglich, vollkommen automatisiert eine .p2-Sitzungsdatei zu erstellen und dann über Kommandozeile ein pdf/svg/png-Diagramm zu erzeugen. Dies ist sehr praktisch, wenn man automatisch eine größere Menge an gleichartigen Diagrammen mit jeweils unterschiedlichen Daten erstellen möchte (siehe Kommandozeilenreferenz).
1.1.2. Diagrammtypen
Mit dem Postprozessing lassen sich verschiedene Diagrammtypen erstellen. Grundsätzlich kann man zwischen 2D- und 3D-Diagrammen unterscheiden, wobei bei 3D-Diagrammen die dritte Dimension als Farbe bzw. Isolinie dargestellt wird. Ebenso sind Vektorfeld-Ausgaben (z.B. von Strömungsfeldern) möglich.
Zeit-Werte Diagramme
In Zeit-Werte Diagrammen ist die X-Achse die Zeitachse und es werden mehrere Kurven darüber angezeigt, wobei auch zwei unterschiedliche Y-Achsen verwendet werden können.
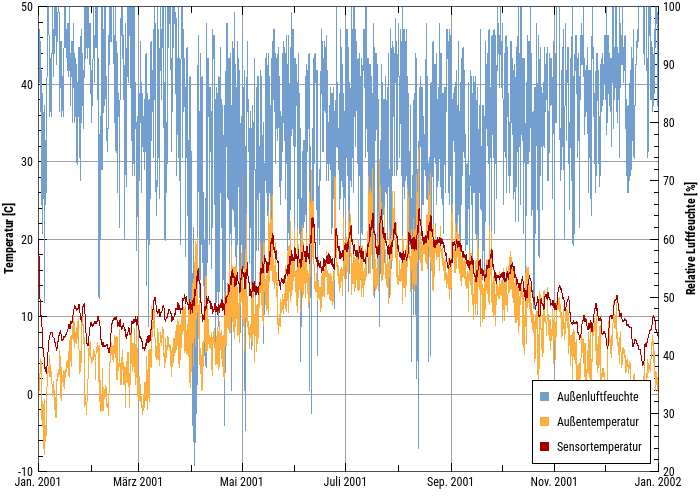
Dies ist ein typisches Zeit-Werte-Diagramm, mit der Zeitachse als Datumsachse formatiert, und zwei Y-Achsen für jeweils Temperatur und Luftfeuchten. Hier können beliebig viele Linien dargestellt werden, solange deren physikalische Einheiten einer der beiden Y-Achsen entsprechen.
Profilschnitte (Koordinaten-Wert-Diagramme)
3D Daten (d.h. Zeit-Koordinate-Wert) können ebenfalls in klassischen 2D Diagrammen dargestellt werden, wobei dabei die X-Achse die Koordinate ist, und die Werte eines bestimmten Zeitpunkts dargestellt werden.
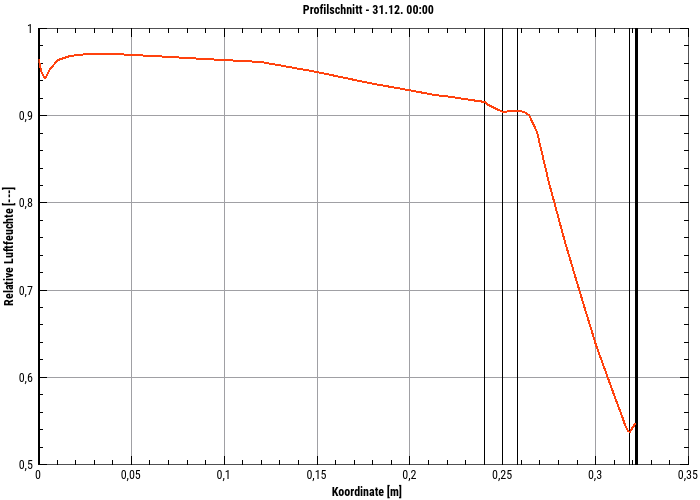
Dies ist ein 2D-Diagramm, welches ein zeitanimiertes Profil einer (oder mehrerer) physikalischer Größen über der Geometrie für jeweils einen ausgewählten Zeitpunkt zeigt. In dieser Darstellung können Konstruktionslinien/Materialschichten durch dünne Linien gezeichnet werden. Der Zeitpunkt kann in der Oberfläche einfach verändert werden und kann so eine Animation zeigen.
Farbverlaufsdiagramme
3D Daten wie oben können auch als Farbverlaufsdiagramme dargestellt werden:
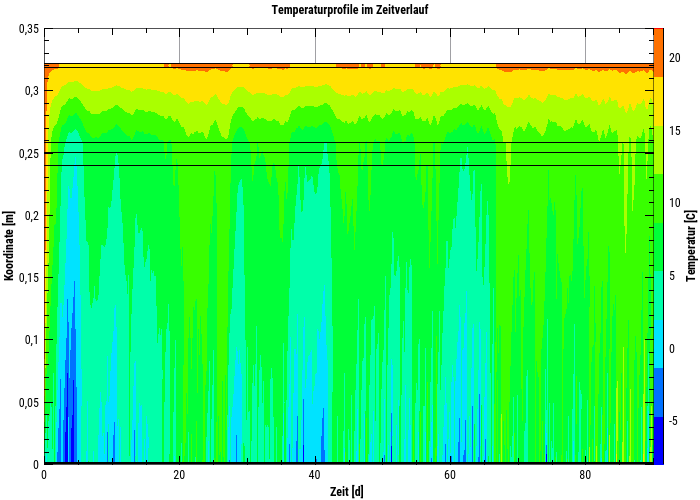
Ein Farbverlaufsdiagramm (3D), welches den zeitlichen Verlauf von Temperaturprofilen darstellt. Die X-Achse ist eine Zeitachse, die Y-Achse die Koordinate und die Farbe repräsentiert die Zahlenwerte (z.B. eine Temperatur).
Darstellung von 2D Geometrien als zeitanimierte Farbverlaufsdiagramme
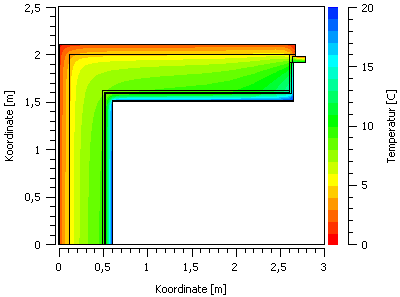
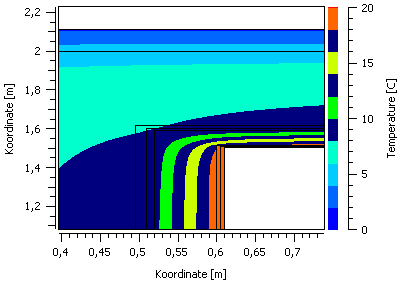
4D Daten (d.h. Zeit-Koordinate-Koordiante-Wert) können in zeitanimierten Farbverlaufsdiagrammen dargestellt werden.
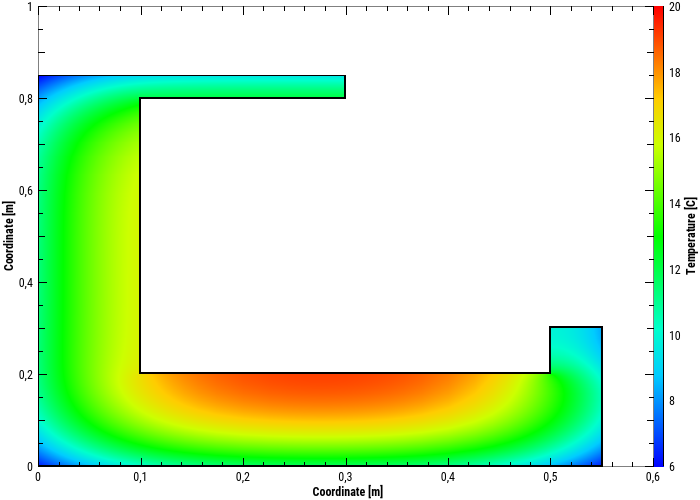
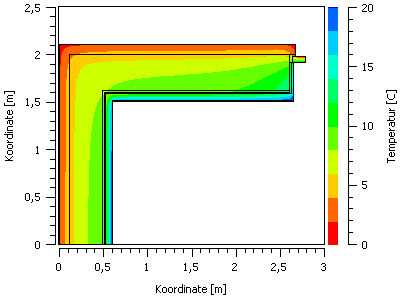
In einem solchen Farbverlaufsdiagrammen, welches hier ein Temperaturfeld für einen ausgewählten Simulationszeitpunkt zeigt, repräsentieren die Achsen hier die Koordinaten, und die Farbe den jeweiligen Wert.
1.1.3. Darstellungskonfigurationen
In PostProc 2 können mehrere Diagramme gleichzeitig dargestellt werden, wobei es bei zeitanimierten Diagrammen möglich ist, in mehreren oder allen Diagrammen gleichermaßen den Zeitpunkt zu ändern. So lassen sich zusammenhängende physikalische Effekte gut analysieren.
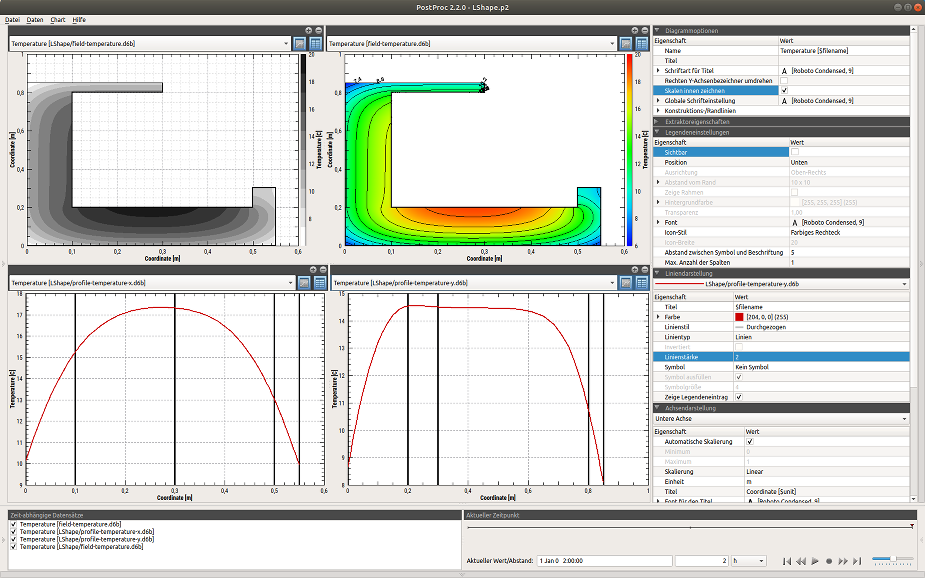
2. Programmoberfläche
Die Benutzeroberfläche untergliedert sich in das Hauptfenster mit einem oder mehreren Diagrammen und den seitlich sowie unten angeordneten Paneelen.
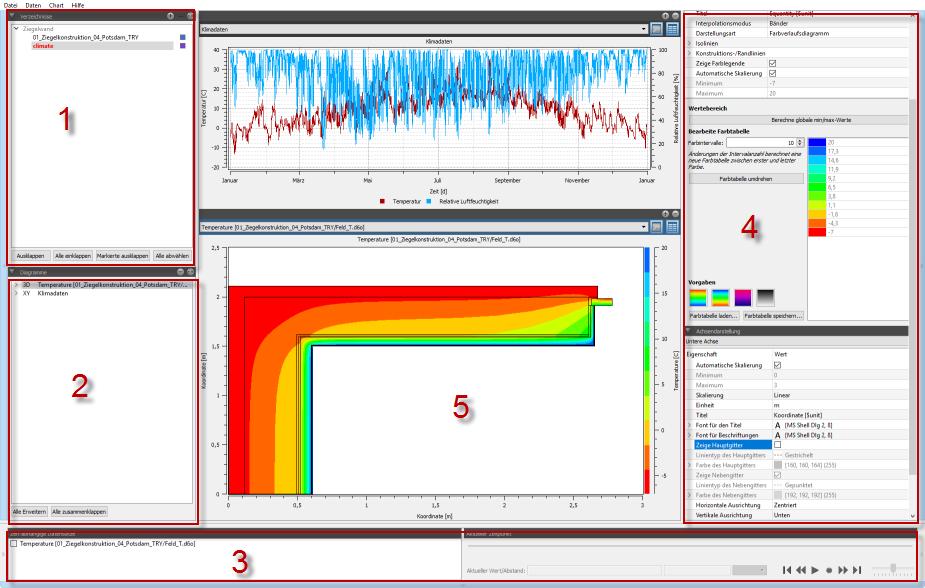
2.1. Elemente der Programmoberfläche
-
Verzeichnisbaum zur Verwaltung der Verzeichnisse mit Datensätzen/Dateien (siehe Datenverwaltung)
-
Übersicht über erstellte Diagramme und darin enthaltene Kurven/Serien (siehe Diagrammverwaltung)
-
Liste aller zeitlich animierbaren Diagramme und Steuerung des aktuell angezeigten Zeitpunkts (siehe Diagrammanimation)
-
Diagrammeigenschaftspaletten (siehe Diagrammformatierung)
-
Diagramm oder Diagramme (siehe Diagrammfenster)
Die Paneele links (1 und 2), rechts (4) und unten (3) können weggeklappt werden, wofür jeweils die Schaltflächen am Rand angeklickt werden können:
|
Mit dem Kurzbefehl |
2.2. Umschalten zwischen Datenmanageransicht und Diagrammansicht
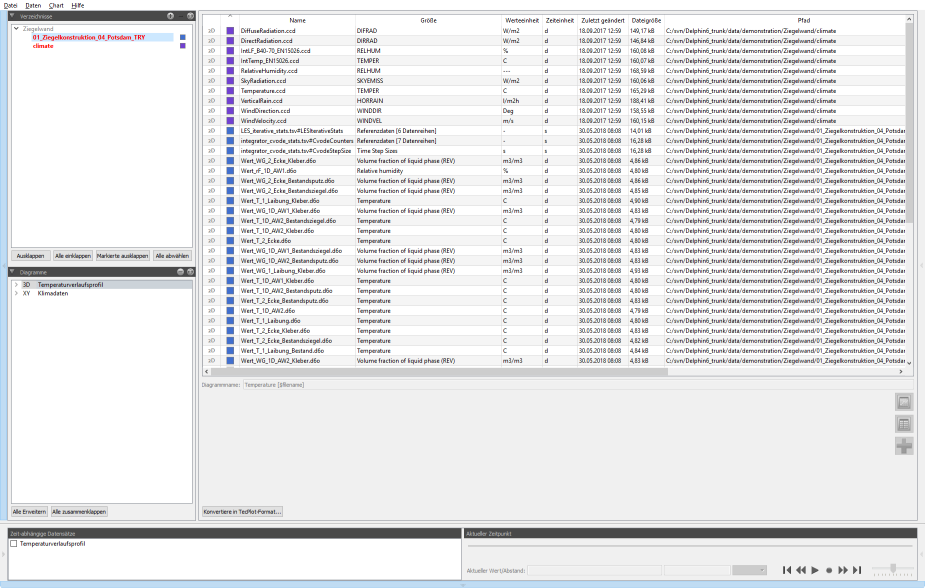
Mit einem Klick auf den Verzeichnisbaum (1) erscheint die Datenmanageransicht, d. h. eine Tabelle mit auswertbaren Datensätzen (siehe Datenverwaltung):
Bei Klick auf die Diagramm-Baumstruktur/Diagrammverwaltung schaltet das PostProzessing in den Diagrammbearbeitungsmodus um (zeigt die verfügbaren Diagramme an).
2.3. Sitzungen
Mit Sitzung wird die Gesamtheit der aktuell in PostProc 2 dargestellten Daten bezeichnet. Dies beinhaltet:
-
hinzugefügte und ausgewählte Datenverzeichnisse (und deren Ausklappzustand),
-
erstellte Diagramme, deren Art und Konfiguration,
-
von den Diagrammen referenzierte Quelldaten und Informationen zur Extraktion der Daten und
-
Programmoberflächeneinstellungen.
Eine Sitzung lässt sich also mit einer Projektverwaltungsdatei vergleichen. Sitzungen werden in Sitzungsdateien mit der Endung p2 abgespeichert (XML-Format).
2.4. Format der Sitzungsdateien
Die Sitzungsdateien sind im XML-Format geschrieben. Normalerweise werden nur die geänderten Daten in die Datei geschrieben. Möchte man jedoch eigene Parameter anpassen, kann man sich zunächst alle Parameter herausschreiben lassen. Dazu muss man im Einstellungsdialog (Datei - Einstellungen) die Option Komplette Sitzungsdatei schreiben anschalten.
Abschnitt Sitzungsdateiformat gibt einen kurzen Überblick über die Struktur der Datei mit Verweisen zu den jeweiligen Handbuchabschnitten mit den Formatdetails.
2.5. Sitzungsdateien in externem Texteditor bearbeiten
Es ist möglich, diese Sitzungsdateien extern im Editor anzupassen und danach neu einzuladen. Auf diese Art und Weise lassen sich skriptbasiert Auswertungssitzungen generieren. Auch können Formatierungseinstellungen eines Diagramms einfach auf ein anderes Diagramm übertragen werden.
Der externe Texteditor kann über den Menübefehl Datei - Bearbeite die Session-Datei in Texteditor oder über den Tastaturkurzbefehl F2 geöffnet werden. Wenn die Sitzungs-Datei extern abgespeichert wurde, fragt das PostProc 2 bei der nächsten Aktivierung nach, ob die geänderte Datei geladen werden soll.
Der zu verwendende Texteditor lässt sich im Einstellungsdialog auswählen.
|
Das Tastaturkürzel |
2.6. Ausgewählte Sitzungsdatei bei Programmstart öffnen
Standardmäßig versucht PostProc 2 bei Programmstart die letzte Sitzungsdatei erneut zu laden. Dieses Verhalten kann im Einstellungsdialog geändert werden, sodass stattdessen mit einer leeren Sitzung begonnen wird.
Möchte man das Post-Prozessing mit einer gewählten Sitzung direkt starten, kann man diese auf der Kommandozeile angeben, z.B.:
> PostProcApp.exe C:\Pfad\zur\Sitzung.p2Siehe auch Kommandozeilenreferenz.
2.7. Benutzerdefiniertes Verzeichnis
Konfigurationsdaten und Nutzerdaten allgemein werden im anwenderspezifischen Datenverzeichnis abgelegt.
Beispielsweise ist dieses Anwenderverzeichnis bei einem Benutzernamen simulant je nach Betriebssystem in den folgenden Orten zu finden:
Plattform |
Pfad |
Windows |
Beispiel: |
Linux |
Beispiel: |
MacOS |
Beispiel: |
2.8. Fehleranalyse/Logdatei
Das PostProzessing arbeitet mit Nutzerdaten, welche auf viele Arten fehlerhaft oder ungeeignet sein können. Falls bei der Verwaltung und Analyse der Daten Fehler auftreten, werden diese nicht über Fehlermeldungsfenster dem Nutzer mitgeteilt, sondern in eine Logdatei bzw. in das Logfenster geschrieben. Der Inhalt der Logdatei ist auch bei Fehlerberichten hilfreich.
Angezeigt wird die Logdatei mittels Menübefehl: Daten - Zeige Logdatei...
Die Logdatei befindet sich im anwenderspezifischen Datenverzeichnis.
2.9. Logfenster im Programm
Das Logfenster befindet sich im unteren Paneel und ist normalerweise nicht sichtbar. Es kann durch Klick auf die untere linke Seitenschaltfläche angezeigt und wieder versteckt werden:
Es gibt Meldungen mit unterschiedlicher Dringlichkeit; manche sind nur informativ, manche sind Fortschrittsmeldungen. Man kann sowohl für die Logdatei als auch für die Logfensterausgaben unabhängig, den gewünschten Detaillierungsgrad der Meldungen einstellen. Dafür gibt es im Einstellungsdialog Datei - Einstellungen die Registerkarte Allgemeine Einstellungen. In diesem Dialog ist auch der Pfad zur Logdatei aufgeführt.
3. Datenimport und Datenverwaltung
Der erste Schritt bei der Erstellung von Diagrammen und Datenanalyse ist die Auswahl der Datensätze und Dateien.
3.1. Der Verzeichnisbaum
3.1.1. Hinzufügen von Verzeichnissen mit auszuwertenden Dateien
Zunächst wird im Verzeichnisbaum (siehe Abb. Verzeichnisbaum) ein (Basis-)Verzeichnis für die Datenauswertung hinzugefügt, welches dann nach unterstützten Ergebnisdateien durchsucht wird.
Verzeichnisse werden über die ![]() Schaltfläche hinzugefügt und mittels
Schaltfläche hinzugefügt und mittels ![]() wieder entfernt.
wieder entfernt.
Beim Hinzufügen eines Verzeichnisses wird dieses und alle Unterverzeichnisse nach auswertbaren Dateien in bekannten Dateiformaten durchsucht.
|
Falls man ein Verzeichnis hinzufügt, in dem sich keine auswertbaren Dateien befinden, bleibt der Verzeichnisbaum unverändert. Grundsätzlich werden Verzeichnisse ohne auswertbare Dateien nicht im Verzeichnisbaum angezeigt. |
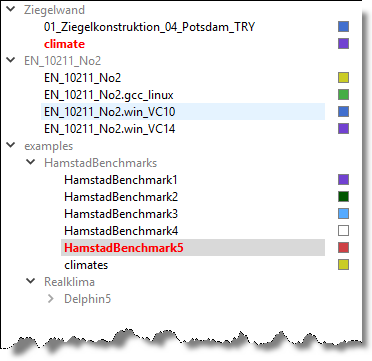
Der Verzeichnisbaum enthält nun alle Verzeichnisse (und deren Unterverzeichnisse) welche Ergebnisdaten beinhalten. Grau geschriebene Verzeichnisse enthalten selbst keine Ergebnisdaten, aber zumindest eines der Unterverzeichnisse (siehe Abb. Farbzuordnungen zu Verzeichnissen). Allen Verzeichnissen mit Daten wird eine Farbe zugeordnet, worüber später die Zuordnung der einzelnen Dateien leicht erkennbar ist.
|
Es können beliebig viele Verzeichnisse hinzugefügt werden. Es ist jedoch nicht möglich, ein Verzeichnis innerhalb einer bereits hinzugefügten Verzeichnishierarchie hinzuzufügen. Ähnlich wie beim Hinzufügen leerer Verzeichnisse, passiert dann einfach nichts. |
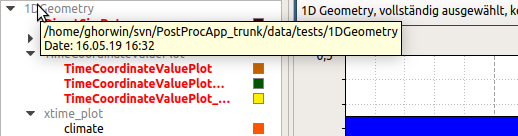
Im Verzeichnisbaum werden nur die Verzeichnisse relativ zum ausgewählten Verzeichnis hinzugefügt. Der absolute Pfad kann man sich jedoch als Tooltip anzeigen lassen:
Simulationsergebnisse von den IBK-Simulationsprogrammen werden in einer projektspezifischen Verzeichnisstruktur abgelegt. PostProc 2 erkennt diese und fasst die Daten übersichtlich zusammen:
|
Verzeichnishierarchien aus DELPHIN, THERAKLES, MASTERSIM, SIM-VICUS/NANDRAD etc.
Eine Besonderheit stellen Simulationsausgabeverzeichnisse aus den IBK Simulationsprogrammen DELPHIN, THERAKLES, NANDRAD und MASTERSIM dar. Dabei enthält das Projektverzeichnis weitere Unterverzeichnisse mit den eigentlichen Daten. Ausgehend von einer Projektdatei projects/
├── RealKlima.d6p
└── RealKlima
├── log
│ ├── integrator_cvode_stats.tsv
│ └── ...
├── results
│ ├── Flux_Feuchte_NORD.d6o
│ ├── ...
│ └── TemperatureSensor.d6o
└── var
├── ...
└── restart.bin
Bei Auswahl des übergeordneten Verzeichnisse 
Abbildung 12. Verzeichnisbaum nach Hinzufügen des Elternverzeichnisses eines Simulationsverzeichnisses
Wählt man beim Hinzufügen hingegen das Verzeichnis 
Abbildung 13. Verzeichnisbaum nach Hinzufügen des Simulationsverzeichnisses selbst
Es ist also empfehlenswert, jeweils das Elternverzeichnis der Simulationsprojektdateien zur Analyse hinzuzufügen. |
3.1.2. Markieren von Verzeichnissen zur Datenanalyse
Im nächsten Schritt werden die zur Analyse ausgewählten Verzeichnisse markiert (Doppelklick auf das Verzeichnis). Dadurch erscheinen die in den Verzeichnissen auswertbaren Dateien/Datensätze in der Datensatz-Tabelle. Gleichzeitig werden die markierten Verzeichnisse im Verzeichnisbaum rot geschrieben (siehe Screenshot in Abb. Verzeichnisbaum). Ein weiterer Doppelklick auf die rot markierten Verzeichnisse entfernt den Inhalt dieser Ordner wieder.
Die Schaltflächen am unteren Rand des Verzeichnisbaums dienen ebenfalls dem Markieren/Abwählen von Verzeichnissen.
|
Aktuell markiertes Verzeichnis zu Analyse auswählen (markieren, wie mit Doppelklick auf ein Verzeichnis) |
|
Markiertes Verzeichnis wieder abwählen (wie mit Doppelklick auf ein markiertes Verzeichnis) |
|
Alle Verzeichnisknoten ausklappen |
|
Alle einklappen |
|
Die Verzeichnisknoten so ausklappen, dass alle markierten Verzeichnisse sichtbar werden |
3.1.3. Die Datenmanager-Ansicht
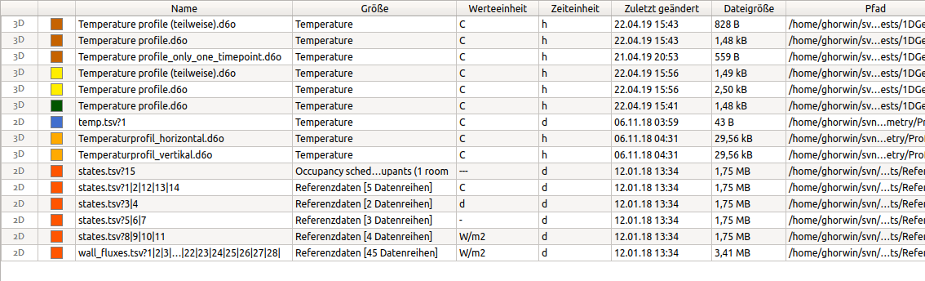
Im Datenmanager werden die verschiedenen Datensätze mit wesentlichen Kenngrößen in einer Tabelle angezeigt. Die erste Spalte gibt den Datentyp an (siehe Datenformate/Datentypen). Die Farbspalte zeigt an, aus welchem Verzeichnis die Datei stammt (bzw. aus welchem Projekt).
|
Die mit einem Verzeichnis assoziierte Farbe kann mit Doppelklick auf das Farbquadrat neben dem Verzeichnis-Knoten im Verzeichnisbaum geändert werden. So lassen sich die individuellen Ausgabedateien auch bei gleichem Dateinamen (z.B. bei einer Variantenstudie) gut auseinanderhalten. |
Die Spalte Größe gibt die in der Datei angegebene physikalische Größe an (nicht Dateigröße!). Dies kann je nach Dateityp ein Schlüsselwort, eine Zeichenkette oder ein generischer Text, z.B. Referenzdaten [2 Datenreihen] sein. Dann folgen zwei Spalten mit den physikalischen Einheiten (Werte- und Zeiteinheit), welche im Datensatz verwendet werden. Danach folgen Dateiattribute.
Bei Referenzdaten bzw. generischen Tabellendaten (z.B. csv oder tsv, siehe Datenformate/Datentypen) können verschiedene Spalten unterschiedliche physikalische Einheiten haben, z.B. C für Grad Celsius bei einer Temperatur und Pa für Pascal bei Druckgrößen. Da je Datensatz/Zeile nur eine Werteeinheit erlaubt ist, wird für jede physikalische Einheit je ein Datensatz aus der Ursprungsdatei erstellt. Der angegebene Dateiname hat dann das Format <Dateiname>?<Suffix>. In der weiteren Verwendung werden derartige Datensätze aber genau wie andere behandelt.
3.1.4. Aktualisierung der Verzeichnisstruktur
Durch externe Programme können neue Ergebnisdaten in die vom Post-Prozessing verwaltete Verzeichnisstruktur gelangen oder Verzeichnisse können entfernt werden. Das Post-Prozessing überwacht die Verzeichnisse nicht automatisch, man kann aber bei Bedarf durch Verwendung der Aktualisierungsschaltfläche ![]() die Verzeichnisstruktur neu einlesen und damit sowohl den Verzeichnisbaum als auch die Datenmanager-Ansicht aktualisieren.
die Verzeichnisstruktur neu einlesen und damit sowohl den Verzeichnisbaum als auch die Datenmanager-Ansicht aktualisieren.
3.2. Datenformate/Datentypen
PostProc 2 kann Daten aus verschiedenen Dateiformaten importieren, welche dann je nach Inhalt als Datensätze mit verschiedenen Formaten interpretiert werden. Dazu hilft es zunächst, die Datentypen und Dateiformate zu kennen, welche PostProc 2 unterstützt, und wie man eigene Daten für die Analyse vorbereitet.
|
Diese Kapitel ist etwas länglich, da im Detail die einzelnen Datei- und Datenformate erklärt werden. Man kann auch gleich zum Kapitel Diagrammerstellung springen und bei Bedarf hier wie in einer Referenz weiterlesen. Interessant ist auf jeden Fall das Kapitel Import eigener 2D Datensätze, in dem einige Methoden beschrieben werden, wie man eigene Daten aus beliebigen Quellen am schnellsten ins Post-Prozessing bekommt. |
3.2.1. Datenformate
2D-Datensätze
Dies sind Zeit-Werte-Paare, aus denen 2D-Diagramme (Zeit, Wert) erstellt werden können. Beispiel dafür sind Sensorwerte, d.h. Ausgaben physikalischer Größen an bestimmten Koordinaten oder Messdaten, integrale Flussgrößen oder allgemein skalare, zeitabhängige Ausgaben.
3D-Datensätze
Dies sind Datensätze mit 3 unabhängigen Variablen, konkret: Zeit-Koordinate-Wert, wobei die Koordinate jeweils für eine Koordinatenachse steht. Beispiel wären Zeit-X-Wert-Daten bzw. Zeit-Y-Wert-Daten.
3D Datensätze können als Ergebnisdaten von Simulationsprogrammen mit partiellen Differentialgleichungen entstehen, und entsprechen hierbei Profilschnitten in X, Y oder Z Richtung.
Im Unterschied zu 2D Datensätzen gibt es je Zeitpunkt mindestens 2 unterschiedliche Koordinaten mit jeweils zugeordneten Werten.
|
Die Verwendung einer Schnittoperation in einer 2D Konstruktion, z.B. beim Festlegen einer Ausgabe in DELPHIN führt nicht zwangsläufig zu einem 3D-Datensatz. Beispielsweise könnte man bei einer 1D Simulation mit Gitter in X-Richtung einen Y-Schnitt festlegen. Da in der Ausgabe dann nur eine Y-Koordinate je Zeitpunkt verwendet wird, erhält man nur einen 2D Datensatz. |
In PostProc 2 ist es möglich, aus einem 3D Datensatz durch Fixierung eines Zeitpunkts oder einer Koordinate einen 2D Datensatz heraus zu schneiden. Beim Festlegen eines Zeitpunkts (time cut) erhält man ein 2D Diagramm mit Koordinate auf der X-Achse und dem Wert auf der Y-Achse.
|
Je nach vorliegendem Datensatz kann bei einem Zeitschnitt die Koordinate entweder X, Y, oder Z-Koordinaten entsprechen. In PostProc 2 wird dennoch die Koordinate immer auf der X-Achse dargestellt, auch wenn es im Falle von Y-Koordinaten (z.B. aus einer horizontalen Dachkonstruktion) zu einer gedrehten Konstruktionsansicht führt. |
Beim Festlegen einer Koordinate (value cut) erhält man ein klassisches 2D Sensordiagramm, mit Zeit auf der X-Achse und Wert auf der Y-Achse. Es ist auch möglich, einen solchen value cut mit anderen 2D Datensätzen zusammen in einem Diagramm darzustellen.
Den kompletten 3D Datensatz kann man in einem Farbverlaufsdiagramm darstellen, wobei hier die X-Achse die Zeit und die Y-Achse die Koordinate ist, und der Wert als Farbe dergestellt wird.
4D-Datensätze
Dies sind Datensätze mit 4 unabhängigen Variablen, konkret: Zeit-Koordinate-Koordinate-Wert. Auch hier ist die Zuordnung einer Achse zu der Koordinate beliebig, also sind XY, YZ, XZ möglich.
Eine Darstellung von 4D Datensätzen in einem Diagramm ist nicht möglich, daher muss zumindest eine der Variablen festgehalten werden. Durch Fixierung des Zeitpunkts, der ersten oder zweiten Koordinate kann man einen 3D-Datensatz extrahieren. Am üblichsten ist die Fixierung des Zeitpunkts, wodurch man zeitanimierte Farbverlaufsdiagramme erhält.
Bei Fixierung von zwei Variablen extrahiert man einen 2D Datensatz.
5D-Datensätze
Solche Zeit-X-Y-Z-Wert-Daten entstehen bei Feldausgaben in Simulationen von 3D Geometrien. Analog zu 4D-Daten muss man zunächst 3D oder 2D Datensätze durch Fixierung von Variablen extrahieren, um diese dann anzeigen zu können.
3.2.2. Dateitypen und Dateierweiterungen
PostProc 2 unterstützt eine ganze Reihe von Dateiformaten für die Angabe von 2D Datensätzen. Für die Angabe von 3D, 4D und 5D Datensätzen wird exklusiv das DataIO-Format verwendet.
Dateien mit folgenden Dateierweiterungen werden von PostProc 2 gelesen und auf auswertbare Daten hin untersucht.
| Dateierweiterung(en) | Beschreibung |
|---|---|
|
ASCII bzw. binäre Ausgabedateien von DELPHIN 5/6 (siehe DataIO-Dateiformat) |
|
Tabulator-getrennte Spalten mit Kopfzeile |
|
Komma-getrennte Spalten mit Kopfzeile |
|
binary table format, Binärdateien mit Daten wie beim TSV-Format |
|
Monitoring-Tools-Variante des csv-Formats (mehrere Kopfzeilen, … ) |
|
Klimadatenkontainer (siehe Klimadateien und Klimadatencontainer) |
|
Klimadaten aus DELPHIN 5/6 (siehe ebenfalls Klimadateien und Klimadatencontainer) |
|
CVODE Solver-Statistikdateien aus DELPHIN 5 |
Zudem gibt es noch spezielle Datenformatleser für die generischen Zeitintegrationsolver-Ausgaben (aus DELPHIN, NANDRAD, THERAKLES und MASTERSIM):
-
integrator_cvode_stats.tsv -
integrator_ImplicitEuler_stats.tsv -
progress.tsv -
LES_direct_stats.tsv -
LES_iterative_stats.tsv
Die Anforderungen an csv und tsv-Dateien (einfach aus Excel, LibreOffice etc. herauskopierbar) sind im nachfolgenden Abschnitt Import eigener 2D Datensätze beschrieben.
Das spezielle csv-Monitoring-File-Format (wird anhand des speziellen Headers erkannt und grundlegend anders ausgewerted als "normale" csv-Dateien) wird in folgender Publikation beschrieben:
Vogelsang, S. ; Söhnchen, A.: Monitoring Tools File Specification, 2016, http://nbn-resolving.de/urn:nbn:de:bsz:14-qucosa-199034
3.2.3. Grundlegende Annahmen
-
Zahlen in textbasierten Eingabedateien werden stets im englischen Zahlenformat erwartet (. als Dezimaltrennzeichen, keine 1000-er Separatoren)
-
Zeichenketten werden als UTF-8-kodiert angenommen
|
Die Zeichenkettenkodierung ist vor allem und Windows und MacOS wichtig, wenn man eigene TSV/CSV-Dateien erstellt (siehe Import eigener 2D Datensätze/generische |
3.2.4. Import eigener 2D Datensätze/generische csv/tsv-Dateien
Die Verwendung eigener Zeitreihen im Post-Prozessing ist denkbar einfach. Man kann z.B. eine Tabelle aus einer Tabellenkalkulation (Excel etc.) einfach in eine Datei kopieren. Dabei werden die einzelnen Spalten automatisch mit Tabulator-Zeichen getrennt abgelegt. Eine solche Datei sollte dann die Dateierweiterung .tsv erhalten. Auch kann man Tabellendaten als csv-Datei abspeichern und diese dann in PostProc 2 einlesen. Nachfolgend werden die kleinen Unterschiede in der Behandlung der csv und tsv-Dateien beschrieben.
Damit das Post-Prozessing die Daten anzeigen und zuordnen kann, müssen diese Tabellendateien eine Kopfzeile mit Spaltenüberschrift haben.
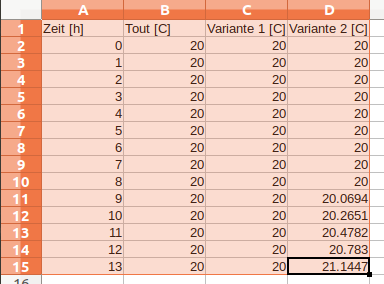
tsv-Datei mit 3 Datenreihen und einer ZeitspalteZeit [h] Tout [C] Variante 1 [C] Variante 2 [C] 0 20 20 20 1 20 20 20 2 20 20 20 3 20 20 20 4 20 20 20 5 20 20 20 6 20 20 20 7 20 20 20 8 20 20 20 9 20 20 20.0694 10 20 20 20.2651 11 20 20 20.4782 12 20 20 20.783 13 20 20 21.1447 ...
Es ist beim tsv-Format unerheblich, ob die Zahlen direkt untereinander stehen, solange sie durch Tabulator-Zeichen voneinander getrennt sind.
Eine solche Datei erhält man automatisch, wenn man eine Tabelle aus einer Tabellenkalkulation kopiert, wie im folgenden Screenshot gezeigt. Hier wurde bereits auf englisches Zahlenformat umgestellt, sonst müsste man danach noch im Texteditor , mit . ersetzen.
|
Es ist wichtig, den Dateien die Endung |
Unterstützte Formatvarianten
Alle Varianten von csv und tsv-Dateien verwenden Zahlen im englischen Format ohne Tausender-Trennzeichen, beispielsweise 12.2, 12e5 oder -1.23e-12.
Folgende Formate werden unterstützt:
tsv oder csv-Endung, Einheiten in Kopfzeile, relative ZeitspalteZeit [h] Tout [C] Variante 1 [C] Variante 2 [C] 0 20 20 20 10 20 20 20.2651 13 20 20 21.1447
tsv oder csv-Endung, Einheiten in Kopfzeile, Zeitspalte mit Datums/ZeitstempelDatum/Zeit Tout [C] Variante 1 [C] Variante 2 [C] 2001-01-01 00:00 20 20 20 2001-06-24 05:00 20 20 20.0694 2001-06-27 05:00 20 20 20.783
|
Eigentlich sollten Dateien mit Tabulator-Zeichen als Spaltentrennzeichen immer die Dateierweiterung |
csv-Endung, ohne Einheitenerkennung, Zeitspalte immer relativ in Sekunden (egal, ob oder welche Zeiteinheit angegeben wird)Zeit [h],Tout [C],Variante 1 [C],Variante 2 [C] 0,20,20,20 9,20,20,20.0694 12,20,20,20.783
|
Eine Angabe einer Zeiteinheit in der Zeitspalte wie |
csv-Endung, Anführungszeichen in Kopfzeile, ohne Einheitenerkennung, Zeitspalte immer relativ in Sekunden"time","outputs[1]","outputs[2]" 0,25,20 0.001,25,20.01 0.002,25,20.02 0.003,25,20.03 0.004,25,20.04
|
Bei Dateien mit kommagetrennten Spalten muss wie im vorangehenden Beispiel davon ausgegangen werden, dass eventuell vorhandene [] ein Teil des Variablennamens sind. Um hier eine Fehlermeldung bei der Einheitenprüfung zu vermeiden, wird bei kommagetrennten Dateien grundsätzlich auf eine Einheitensuche in der Kopfzeile verzichtet. Daher muss bei Verwendung von Einheiten in der Kopfzeile (siehe nachfolgendes Kapitel) unbedingt die Tabulator-getrennte |
Format und Inhalt der Kopfzeile bei tsv-Dateien
Eine Text-Datendatei muss zwingend eine (und nur eine) Kopfzeile enthalten. Ab der 2. Zeile folgen die Daten ohne weitere Leerzeile.
Die erste Spalte ist stets die Zeitspalte, wobei man entweder relative Zeitabstände angeben kann, oder Zeitstempel (siehe Zeitspalte).
Alle weiteren Spalten sind Datenspalten.
|
Die Anzahl der Spalten wird aus der Kopfzeile bestimmt (Anzahl der mit Tabulator getrennten Zeichenketten). Alle Datenzeilen müssen zwingend die gleiche Anzahl an Spalten (d.h. gleiche Anzahl an Tabulatorzeichen) haben. |
Damit PostProc 2 Ausgabegrößen sinnvoll auf Achsen verteilen bzw. Einheiten ineinander umrechnen kann, sollte man für jede Spalte (=physikalische Größe) eine Einheit angeben. Dafür kann man in der Spaltenüberschrift eine Einheit innerhalb eckiger Klammern angeben. Ein Beispiel für eine solche Kopfzeile ist:
Zeit [d] <tab> Außentemperatur [C] <tab> Innentemperatur [C] <tab> Innenluftfeuchte [%]
(<tab> entspricht dem Tabulatorzeichen).
In der Datenmanagertabelle würde diese Datei in zwei Zeilen aufgeteilt dargestellt werden, einmal mit der Einheit C und einmal mit der Einheit %.
|
Enthält eine Spaltenüberschrift keine eckigen Klammern, so wird die Variable als einheitenlos - verwaltet. |
Zeitformate in tsv-Dateien
In tsv-Dateien kann man den Zeitpunkt eines Datenpunkts grundsätzlich auf 2 verschiedene Arten angeben:
-
Zeitpunkte werden relativ durch Angabe eines Zeitabstands in einer gegebenen Einheit angegeben. Diese Einheit (s, min, h, d, a, …) muss in der Kopfzeile der ersten Spalte angegeben werden, beispielsweise "Zeit [h]". Wenn man einen solchen relative definierten Datensatz in einer Datums-/Zeitachse darstellen möchte, muss man einen Null-Zeitpunkt festlegen (siehe Achsendarstellung).
-
Zeitpunkt werden mittels Zeitstempeln als absolute Zeitpunkte angegeben. In diesem Fall darf die Überschrift der ersten Spalte keine Zeiteinheit enthalten, und die Zeitpunkte sind also Zeichenketten im Format
yyyy-MM-dd hh:mmbzw.yyyy-MM-dd hh:mm:ssanzugeben. Ein Beispiel für eine solche Zeitspalte ist oben gezeigt.
3.2.5. Binäre Tabellendaten
Die als tsv/csv-gespeicherten Tabellendaten können (bei größeren Datensätzen) auch im Binärformat gespeichert werden. Diese btf-Dateien sind wie folgt strukturiert Zuerst folgt der Header:
8 Byte - der Magic Header mit dem Inhalt "BTABRLZ!"
4 Byte - unsigned int - Startjahr der Daten (bspw. 2021)
4 Byte - Anzahl der Zeichen der Kopfzeile (n)
n Bytes - KopfzeileDie Kopfzeile ist eine Zeichenkette, in der die einzelnen Kapitelüberschriften mit Tabulatoren getrennt sind, wie in Format und Inhalt der Kopfzeile bei tsv-Dateien beschrieben.
Dann folgen beliebig viele Dateneinträge, für jeden abgelegten Zeitpunkt (entsprechend der Zeilen in den TSV-Dateien).
4 Byte - Anzahl der Zahlen im Record (nVals)
nVals * 8 Byte Fließkommazahl (double) - die eigentlichen ZahlenwertenVals entspricht der Anzahl der Spaltenüberschriften, die in der Kopfzeile angegeben wurden. Die erste Zahl ist der Zeitpunkt als Offset zu Mitternacht, 1. Januar im Startjahr. Bei zyklischen Daten ist das Startjahr egal und man kann hier z.B. 2021 schreiben (jedenfalls kein Schaltjahr).
3.2.6. Klimadateien und Klimadatencontainer
Die in einer Klimadatei enthaltenen Daten werden als individuelle Datensätze dargestellt.
|
Klimadaten werden grundsätzlich als Momentanwerte interpretiert. Zum Beispiel, in einer EPW-Datei ist der erste Zeitpunkt 2000,01,01,1,60 und bedeutet 01.01.2000, 1. Stunde, 60. Minute der 1. Stunde, d.h. Ende der ersten Stunde. Damit werden die in dieser Zeile angegebenen Klimadaten zum Zeitpunkt 01.01.2000 1:00 angezeigt. Falls eine andere Interpretation gewünscht wird, z.B. Mittelwertannahme etc., muss man die Daten vorher bearbeiten (z.B. in einer Tabellenkalkulation) und zeitlich verschieben. |
3.2.7. Das DataIO-Format
Das Dateiformat der out-, d6o- und d6b-Dateien einschließlich der referenzierten Geometriedateien (g6o und g6b-Dateien) ist in folgender Publikation beschrieben:
Vogelsang, S.; Nicolai, A.: Delphin 6 Output File Specification, http://nbn-resolving.de/urn:nbn:de:bsz:14-qucosa-70337
Im Vergleich zum oben beschriebenen tsv-Format enthalten 2D DataIO-Container zusätzliche Headerdaten, sind aber sonst inhaltlich vergleichbar (tsv-Dateien sind normalerweise leichter erstellt).
3D, 4D und 5D Datensätze können nur in DataIO-Containern abgelegt werden. Die PostProc 2 Beispieldaten und -diagramme können hier als Vorlage und zusätzlicher Erläuterung zu dem oben zitierten technischen Bericht dienen.
3.2.8. Gruppierung von Datensätzen nach Werteeinheit
Unabhängig von der Datenquelle versucht PostProc 2 Spalten (d.h. Datenreihen) mit der gleichen physikalischen Einheit gruppiert darzustellen. Dabei ist die Reihenfolge der Datenreihen in der Datei egal.
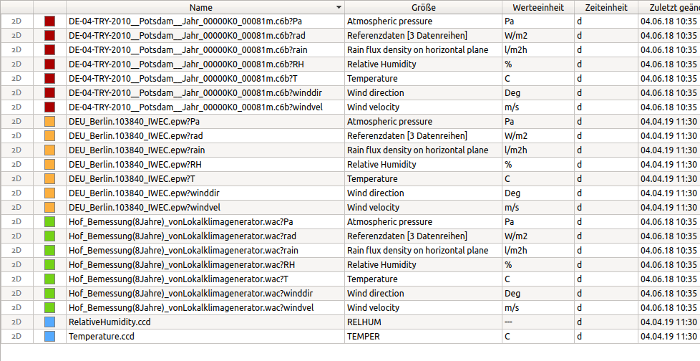
In Abbildung Anzeige von Klimadaten kann man sehr gut sehen, wie aus einer einzelnen Datei mehrere Datensätze extrahiert werden. Die Strahlungsdaten (alle mit Einheit W/m2) werden dabei je Datendatei gruppiert in einem Datensatz dargestellt. Der Text Referenzdaten [3 Datensätze] in der Spalte Größe deutet an, dass sich in diesem Datensatz mehrere Datenreihen befinden.
|
Die Gruppierung gleichartiger physikalischer Größen in einer Zeile der Datensatztabelle ist sehr praktisch bei Analysen von großen Gebäuden mit vielen Zonen. Hier werden dann alle Zonentemperaturen in jeweils einem Datensatz zusammengefasst und man behält in der Datensatztabelle den Überblick. |
Die Auswahl eines oder mehrerer Datenreihen aus einem gruppiert dargestellten Datensatz erfolgt bei der Erstellung eines Diagramms (siehe Erstellung von Diagrammen).
3.2.9. Spaltenidentifikation bei gruppierten Datensätzen
Die Gruppierung von Datensätzen nach Einheit kann dazu führen, dass verschiedene Spalten einer tsv-Datei in verschiedenen Zeilen (Datensätzen) erscheinen. Dann erscheint der Name der Ursprungsdatei mehrfach und unterscheidet sich in den angehängten Spaltennummern.
Beispielsweise wird eine Datei Sensordaten.tsv mit Inhalt:
Zeit [h] T1 [C] T2 [C] RH 1 [%] 0 20 12 55 1 22 13 56
wie folgt in der Dateiliste angezeigt:
Sensordaten.tsv?1|2 Sensordaten.tsv?3
Das Fragezeichen dabei, dass nur einzelne Spalten aus der Datei in dieser Datensatzzeile zusammengefasst sind. Danach folgen durch | getrennten Spaltennummern, wobei die erste Datenspalte (nach der Zeitspalte) den Index 1 hat. Im Beispiel oben sind also die beiden Temperaturspalten im ersten Datensatz gruppiert und der zweite Datensatz enthält die Luftfeuchtespalte RH 1.
3.2.10. Fehleranalyse
Es kommt gelegentlich vor, dass eigene Auswertungsdateien in PostProc 2 als fehlerhaft betrachtet werden und nicht angezeigt werden. Meist kann man durch halten der Maus über dem Dateinamen einen Tooltip mit einer kurzen Fehlermeldung erhalten:

Zusätzlich kann man noch ins Logfenster schauen:
4. Erstellung von Diagrammen
Sobald Datensätze im Datenverwaltungsfenster sichtbar sind, können daraus Diagramme oder Tabellen erstellt werden.
Grundsätzlich lassen sich Diagramme aus einzelnen oder mehreren Datensätzen erstellen. Letzteres ist dann sinnvoll, wenn in einem 2D-Diagramm mehrere Linien gleichzeitig angezeigt werden sollen. Dabei kann man gleich beim Erstellen des Diagramms mehrere Datensätze/Datenreihen auswählen, oder später Datenreihen zu einem existierenden Diagramm hinzufügen.
4.1. Erstellung eines Diagramms
Zur Erstellung eines Diagramms wählt man zunächst einen Datensatz aus der Datensatzliste aus. Ein Bereich von benachbarten Datensätzen lässt sich über Shift+Klick oder Shift+Halten-und-Cursor-Tasten-Bewegen auswählen. Einzelne Datensätze können mittels Strg+Klick dazugenommen werden.
|
Das Erstellen eines Diagramms ist nur möglich, wenn die ausgewählten Datensätze vom Typ her kompatibel sind. Auch können 3D-Farbverlaufsdiagramme stets nur einen Datensatz gleichzeitig darstellen, weswegen eine Mehrfachauswahl hier nicht erlaubt ist. |
Sind einzelne Datensätze oder zueinander passende Daten ausgewählt, wird unter der Datensatztabelle der 2D- bzw. 3D-Konfigurator für die Datenextraktion angezeigt. Je nach Quelldaten können hier bestimmte Einstellungen getroffen werden. Diese bestimmen die Art, wie z.B. aus einer 4D-Datendatei ein 2D-Datensatz extrahiert werden soll. Details zu diesen Einstellungen sind auf den Seiten für 2D-Diagramme bzw. 3D-Diagramme erläutert.
Zuletzt kann noch ein Bezeichner für das Diagramm angegeben werden, wobei der Name Platzhalter enthalten kann. Bei 2D Diagrammen kann man auch noch einen Vorgabenamen für die einzelnen Linien angeben, wobei natürlich die Verwendung von Platzhaltern sinnvoll ist.

Sind alle Eingaben gemacht, kann über den Klick auf das Diagrammsymbol ![]() unten rechts ein Diagramm erstellt werden. Danach schaltet PostProc 2 in die Diagrammansicht um.
unten rechts ein Diagramm erstellt werden. Danach schaltet PostProc 2 in die Diagrammansicht um.
|
Hintergrundinformationen zu Diagrammen und Extraktoren
Ein Diagramm und die dazugehörige Tabellenansicht beschreiben letztlich, wie die Rohdaten zu interpretieren und darzustellen sind. Diese Informationen sind letztlich Anweisungen, wie man aus einer Datensatzdatei die Daten herausholt und darstellt. Dies schließt auch Einheitenumrechnungen ein, und Informationen dazu, wie Daten aus Datenfelden auszuschneiden sind oder ob Modellberechnungen gemacht werden. Diese Anweisungen können bei veränderten Rohdaten jederzeit neu angewendet werden, wodurch eine Aktualisierung der Daten ohne erneutes Festlegen aller Einstellungen sehr komfortabel möglich ist. Der erste Schritt bei dieser Art der Datenbehandlung ist das Herausschneiden (bzw. Extrahieren) der Daten aus den Rohdaten. Dafür werden beim Erstellen des Diagramms (bzw. beim Hinzufügen eines Datensatzes zu einem existierenden Diagramm) Extraktoren konfiguriert. Diese Extraktoren sind Teil der Datenreiheneigenschaft. Beispielsweise wird festgelegt, dass durch Schnitt an einer bestimmten x-Koordinate aus einem 3D-Datensatz ein 2D-Datensatz (Zeit-Wert-Kurve) herausgeschnitten wird. Zusätzlich zu den Extraktionsinformationen wird separat festgelegt, wie die extrahierten Daten darzustellen sind. Bei Liniendiagrammen sind das z.B. die zahlreichen Linieneigenschaften, und auch die Zuordnung zur linken oder rechten Diagrammachse. Die Information über die Erstellung und Konfiguration von Diagrammen wird in der Sitzungsdatei gespeichert, und wird dann bei veränderten Eingangsdaten (Datensätzen) jeweils angewendet. |
4.2. 2D-Diagramme
2D-Diagramme sind im PostProzessing immer Liniendiagramme (auch wenn diese im Erscheinungsbild verändert werden können). D. h. es werden in einem Diagramm mehrere Serien mit der gleichen X-Achse, jedoch möglicherweise unterschiedlichen Y-Achsen angezeigt. Es sind maximal 2 Y-Achsen möglich. Wird nur eine verwendet, ist das ausschließlich die linke Y-Achse.
|
Die Begriffe Linie, Serie, Kurve, Datenreihe werden in diesem Kontext alle synonym verwendet. |
Jeder Serie wird eine Y-Achse zugeordnet, wobei alle Kurven einer Y-Achse auch die gleiche physikalische Einheit haben müssen. In einem Diagramm können also maximal zwei unterschiedliche Werteeinheiten verwendet werden.
Die X-Achse kann entweder eine Zeitachse sein, wenn man z. B. skalare Größen wie Sensordaten über der Zeit darstellt. Oder es kann eine Koordinatenachse sein, wenn man Profile über einer 1D-Geometrie zeitlich animiert darstellt. Dabei entsprechen dann alle angezeigten Serien einem ausgewählten Zeitpunkt.
Bei der Erstellung eines 2D-Diagramms muss man die gewünschten Serien aus den Datensätzen auswählen. Bei Datensätzen mit mehreren Spalten besteht zudem die Möglichkeit, einzelne Spalten (=Serien) auszunehmen oder nur bestimmte auszuwählen. Diese Auswahl wird im 2D-Diagramm-Konfigurationsfenster getroffen, welches unterhalb der Datensatztabelle angezeigt wird:
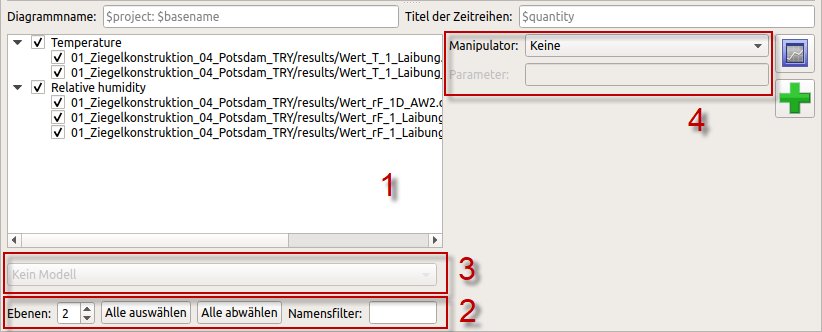
Dieses Fenster enthält eine Anzahl von Elementen:
| [1] |
Im Baumfenster können die zu verwendenden Serien ausgewählt werden |
| [2] |
Filter- und Gruppierungsoptionen (2); der Namensfilter sucht nach Serienbezeichnern, welche den eingegebenen Filtertext enthalten und zeigt nur diese an, die Darstellung in Ebenen ermöglicht eine gruppierte Aus- bzw. Abwahl von Serien (siehe Abschnitt Gruppierungsregeln). |
| [3] |
Unterhalb des Baumfensters kann in der Auswahlliste bei geeignet ausgewählten Datenserien noch eine Modellumrechnung ausgewählt werden (siehe Abschnitt Modelle) |
| [4] |
Rechts davon befindet sich eine Auswahlliste mit Optionen zu Manipulatoren, d.h. Berechnungs- und Umrechnungsregeln für einzelne Datensätze (siehe Abschnitt Manipulatoren) |
4.2.1. Gruppierungsregeln
Zunächst werden alle Serienbezeichner welche einen . (Punkt) enthalten, an diesem Punkt aufgetrennt und in Gruppierungsebenen einsortiert. Stimmen die Bezeichner einer Ebene von 2 oder mehr Serien überein, wird eine Ebene angezeigt (bis zur maximal angegeben Ebenenstufe im Fenster).
Beispiel: Es werden insgesamt 6 Serien aus zwei Dateien mit den Bezeichnern für Temperatur (LT) und relative Luftfeuchtesensoren (LR) ausgewählt:
Datei: grouping.tsv Erdgeschoss.LT1 Erdgeschoss.LT2 Dachgeschoss.XL1 Erdgeschoss.LR1 Erdgeschoss.LR2 Datei: grouping2.tsv Erdgeschoss.LT3
Dies ergibt die folgende Gruppierung:
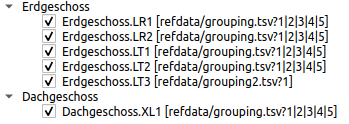
Sind die Serienbezeichner gleich, zum Beispiel bei Variantenstudien, wird der Serienbezeichner als oberste Ebene angelegt und die konkreten Dateinamen als zweite Ebene. Werden nur Datensätze aus einer Datei ausgewählt, so entfällt die Angabe der Quelldatei.
|
Die im Beispiel dem Dateinamen folgende Zahlen |
4.2.2. Auswahl der Y-Achsen
Sollen mehrere physikalische Größen im Diagramm dargestellt werden, so werden die Achsen nach der Reihenfolge der hinzugefügten Serien belegt. Die zuerst zugefügte Serie wird der linken Y-Achse zugeteilt und entsprechend wird dieser Achse eine Einheit zugeordnet. Wir eine weitere Serie hinzugefügt, deren Einheit in diese Achseneinheit umrechenbar ist, so wird auch die linke Y-Achse verwendet. Pass die Einheit nicht zur linken Y-Achseneinheit, wird die Serie und deren Einheit dann der rechten Y-Achse zugeordnet. Alle weiteren Serien werden entsprechend ihrer Einheiten zu den Achsen zugeordnet.
|
Man kann später die linke und rechte Achse tauschen, siehe Abschnitt Y-Achsenzuordnung tauschen. |
Die Einheitenumrechnung und die im PostProc 2 unterstützten Einheiten sind im Abschnitt Einheitensystem beschrieben.
4.2.3. Ungültig hinzugefügte Serien
Sollten die ausgewählten Datensätze mehr als 2 inkompatible Werteeinheiten haben, so werden Serien solange zum Diagramm hinzugefügt, bis beide Y-Achsen belegt sind. Alle weiteren werden als fehlerhaft markiert, und ein Tooltip (Maus darüber halten) gibt den Grund für den Fehler aus:

4.2.4. 2D-Diagramme aus 3D/4D/5D-Datensätzen
Auch aus 3D-Datensätzen (oder 4D oder 5D-Datensätzen) können 2D-Diagramme erstellt werden. In diesem Fall muss eine Schnittebene festgelegt werden, welche üblicherweise ein zeitanimiertes 2D-Profildiagramm ergibt.
Eine 1D-Geometrie (z.B. vertikale Wand) wird simuliert und es entsteht ein 3D-Datensatz mit Zeit, Koordinate (entlang der X-Achse) und Werten. Definiert man als Schnittebene die X-Werte-Ebene bzw. einen Zeitschnitt (TimeCut), so ergibt sich für jeden Zeitpunkt im Datensatz ein 2D-Diagramm (Profil). Dabei wird auf der X-Achse die Koordinate dargestellt und auf der Y-Achse die Werteskala.
Der aktuell angezeigt Zeitpunkt lässt sich über die Zeitanimationskontrolle im unteren Paneel ändern.
Bei Auswahl eines 3D/4D/5D-Datensatzes wird unten ein Diagramm-Konfigurationsfenster angezeigt, in welchem man zunächst zwischen Farbverlaufsdiagramm und Linien-/Profildiagramm wählen kann. Um ein 2D-Diagramm zu erzeugen, muss hier Linien-/Profildiagramm ausgewählt sein. Werden mehrere 3D-Datensätze markiert, ist ein Linien-/Profildiagramm die einzige Auswahlmöglichkeit.

Zuletzt muss der Ebenenschnitt festgelegt werden. Danach kann das Diagramm wie bisher beschrieben über die Schaltfläche rechts erstellt werden.
Analog dazu erfolgt die Erstellung eines 2D Diagramms aus einem 4D oder 5D Datensatz. Hierbei sind jeweils zwei bzw. drei Koordinaten festzuhalten, welches sich in der Bezeichnung der Schnittline ausdrückt. Beispielsweise wird bei einem XT-Schnitt (XTCut) der Zeitpunkt und die X-Koordinate festgehalten.
|
Die Schnittkoordinaten lassen sich jederzeit in den Extraktoreinstellungen anpassen. |
4.2.5. Hinzufügen von Datensätzen zu existierenden Diagrammen
Im Datenverwaltungsfenster mit der Datensatzliste ist es möglich, Datensätze zu existierenden 2D-Diagrammen hinzuzufügen:
-
zuerst ein Diagramm im Diagrammbaum (links unten) auswählen (aktivieren),
-
durch Klick auf den Verzeichnisbaum (links oben) in die Datenmanageransicht in der Mitte wechseln,
-
ein oder mehrere hinzuzufügende Datensätze auswählen,
-
auf
Hinzufügen-Schaltfläche klicken.
klicken.
Grundsätzlich gilt, dass man Datensätze nur zu 2D Diagrammen hinzufügen kann. Außerdem muss die Werteeinheit zu einer der beiden Y-Achsen passen, oder es muss eine Y-Achse noch nicht benutzt sein.
|
Falls man versucht, einen unpassenden Datensatz hinzuzufügen, erscheint bei Klick auf die |
4.2.6. Daten-Manipulatoren
Rechts von der Liste der hinzuzufügenden 2D-Datenreihen sind Optionen zur Konfiguration von Datenreihen-Manipulatoren angegeben.
Manipulatoren sind Vorschriften, wie die Datenreihen vor der Anzeige im Diagramm zu verändern bzw. umzurechnen sind. Diese Berechnungsvorschriften werden bei jeder Datenaktualisierung angewendet. Wenn sich also die Rohdaten ändern, und diese beim Aktualisieren der Daten neu eingelesen werden, so werden auch die Manipulationsregeln abgearbeitet, bevor die Daten ans Diagramm übergeben werden.
|
Beim Erstellen eines Diagramms, bzw. beim Hinzufügen von Datenreihen werden konfigurierte Manipulatoren für jede Datenreihe individuell festgelegt. |
Folgende Manipulationsoperationen gibt es:
Manipulator: Differenz zwischen aktuellem und erstem Wert
Hier wird in einer Datenreihe jeweils der erste Wert (meist Zeitpunkt 0) vom jeweils aktuellen Wert abgezogen, also Beispielsweise:
Time [h] Original [-] Manipuliert [-] 5 12 0 6 17 5 8 18 6 10 11 -1
Dieser Manipulator ist sinnvoll, wenn Massen- oder Energiedifferenzen zum Anfangszustand bestimmt werden sollen, bspw. bei der Analyse von Wasseraufsaugversuchen.
Manipulator: Skalierung durch Faktor
Hier wird der jeweilige Zahlenwert der originalen Datenreihe mit einem Faktor multipliziert.
Beispiel, bei Verwendung des Faktors -1:
Time [h] Original [-] Manipuliert [-] 0 0 0 1 2.5 -2.5 2 4.2 -4.2 3 8.5 -8.5
Dieser Manipulator ist z.B. sinnvoll, wenn man bei Flussausgaben eine Vorzeichenkorrektur machen möchte, um z.B. Vergleiche zwischen Flussgrößen mit unterschiedlichen Vorzeichendefinitionen zu machen.
Manipulator: Offset (Werteverschiebung)
Mit diesem Manipulator können Datenreihen um einen konstanten Wert verschoben werden.
Beispiel, bei Verwendung eines Verschiebungswerts von -2:
Time [h] Original [-] Manipuliert [-] 0 0 -2 1 2.5 0.5 2 4.2 2.2 3 8.5 6.5
Mit diesem Manipulator kann man Datenreihen vertikal verschieben. Dies ist unter anderem sinnvoll, um Toleranzbänder darzustellen. In diesem Fall kann man die gleiche Datenreihe mehrfach unter Verwendung eines unterschiedlichen Verschiebungswerts zum Diagramm hinzufügen.
|
In der aktuellen PostProc 2-Version können Manipulatoren noch nicht in der Programmoberfläche angepasst/verändert werden, oder nachträglich zu Datenreihen hinzugefügt werden. Man kann also derzeit nur eine Datenreihe entfernen und mit neu konfiguriertem Manipulator erneut hinzufügen. Praktischer ist es jedoch, die Manipulatordefinition direkt in der Sitzungsdatei zu ändern. Siehe dazu Dokumentation in Abschnitt Sitzungsdateiformat. |
4.3. 3D-Diagramme
3D-Diagramme können aus 3D, 4D oder 5D-Datensätzen erstellt werden, wobei stets ein Farbverlaufsdiagramm erstellt wird.
Bei Diagrammen aus 3D-Datensätzen wird die Zeit auf der X-Achse aufgetragen, die Koordinate (egal ob X-, Y- oder Z-Koordinate) auf der Y-Achse, und die Werte werden in Farbwerte umgerechnet dargestellt.
Bei Diagrammen aus 4D oder 5D-Datensätzen besteht im Konfigurationsfenster wieder die Möglichkeit, einen Schnitt zu definieren.
|
Es ist nicht möglich (oder sinnvoll) zwei 4D-Datensätze gleichzeitig in einem Farbverlaufsdiagramm darzustellen. Bei Auswahl von zwei oder mehr 4D-Datensätzen ist daher das Konfigurationsfenster deaktiviert. |
4.4. Vektorfelddiagramme
Aus Datensätzen mit Vektorfeldern können entsprechende Vektorfelddiagramme erstellt werden:
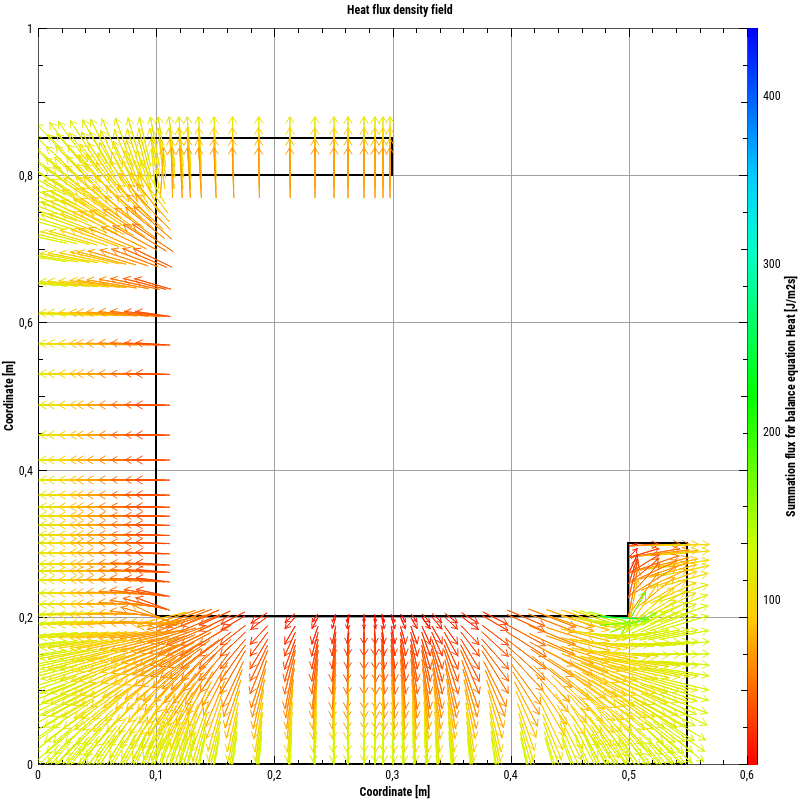
Bei Vektorfelddaten gibt es eine Vielzahl von Anpassungsmöglichkeiten in der Eigenschaftspalette:
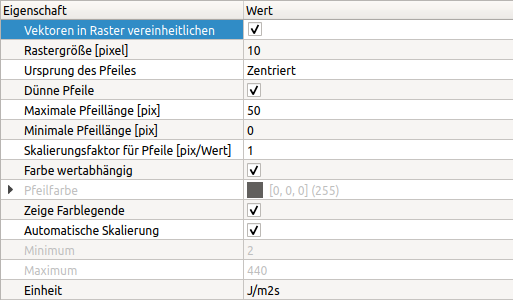
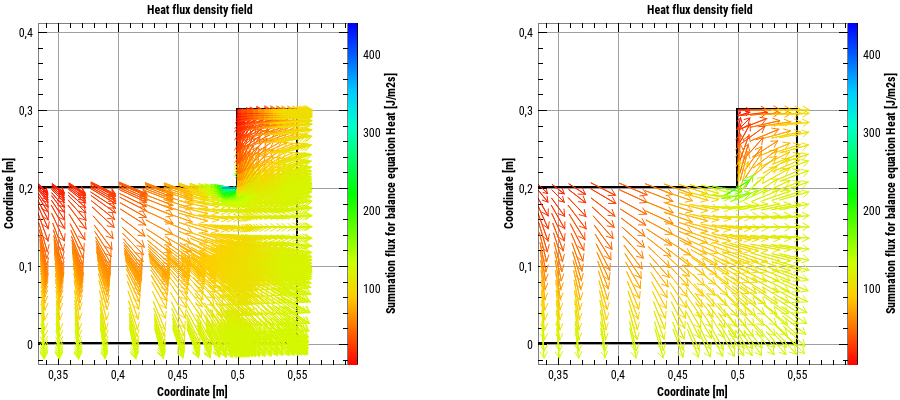
Vektorfelddaten sind meist bezogen auf ein Berechnungsgitter abgelegt. Wenn für jeden Datenpunkt die Vektorpfeile gezeichnet werden, kann dies zu einer hohen Pfeildichte führen, bei der man nichts mehr erkennt. Deshalb kann man auch in einem Raster alle Pfeile zusammenfassen und im Rastermittelpunkt den gemittelten Pfeil in Ausrichtung und Länge zeichnen. Dies wird durch die Option Vektoren im Raster vereinheitlichen eingeschaltet. Die folgende Abbildung zeigt den Vergleich zwischen nativer und rasterbasierter Pfeildarstellung:
5. Diagrammverwaltung
5.1. Diagramm-Baumstruktur
Unterhalb des Verzeichnisbaums werden die erstellten Diagramme in einer Baumansicht dargestellt. Die oberste Ebene entspricht immer dem Diagramm; es wird der Diagrammbezeichner angezeigt (Eigenschaft Name in Diagrammformatierung).
|
Das Verzeichnisbaum und Diagrammbaumfenster können in der Höhe verstellt werden, wenn man mit der Maus zwischen den beiden Fenster am Griff nach oben/unten zieht (siehe verändertes Maussymbol im Screenshot oben). |
Mit den Schaltflächen ![]() kann der Inhalt der einzelnen Diagramme in der Baumansicht aufgeklappt oder geschlossen werden.
kann der Inhalt der einzelnen Diagramme in der Baumansicht aufgeklappt oder geschlossen werden.
5.2. Diagramme und Serien/Linien
Die im Diagramm dargestellen Linien bzw. Serien sind unterhalb des Diagramm-Knotens dargestellt.. Farbverlaufsdiagramme haben hier stets nur einen Eintrag.
Es ist stets immer ein Diagramm aktiv/ausgewählt. Zudem ist immer auch ein Datensatz ausgewählt/aktiv, bei Liniendiagrammen ist also immer eine Linie/Serie aktiv. Die Auswahl entspricht der im Eigenschaftsfenster für Liniendiagramme ausgewählten Linie.
|
Die Reihenfolge, in der Datensätze bzw. Serien/Linien hinzugefügt werden, bedingt die Zeichenreihenfolge. Die Linien werden in einem Diagramm in der Reihenfolge gezeichnet, wie sie im Diagrammverwaltungsbaum aufgeführt sind. Das Verschieben einer Linie innerhalb eines Diagramms wirkt sich auf die Reihenfolge der Linien in der Legende aus sowie auf die Zeichenreihenfolge im Diagramm selber. |
Mit Hilfe der beiden Schaltflächen ![]() können sowohl Diagramme in der Baumansicht als auch Linien innerhalb eines Diagramms verschoben werden.
können sowohl Diagramme in der Baumansicht als auch Linien innerhalb eines Diagramms verschoben werden.
5.3. Entfernen von Serien und Diagrammen
Über die Minus-Schaltfläche ![]() lassen sich einzelne Linien/Serien entfernen. Wird die letzte Serie entfernt, so wird damit auch das Diagramm gelöscht. Ist der Diagrammknoten selbst markiert, so wird das Diagramm mit allen Serien/Linien gelöscht.
lassen sich einzelne Linien/Serien entfernen. Wird die letzte Serie entfernt, so wird damit auch das Diagramm gelöscht. Ist der Diagrammknoten selbst markiert, so wird das Diagramm mit allen Serien/Linien gelöscht.
5.4. Achsentausch und Profilverdopplung
Die meisten Diagramm- und Datenreiheneinstellungen werden in den verschiedenen Eigenschaftsfenstern vorgenommen.
Bei 2D Diagrammen kann man die Zuordnung der Y-Achsen (falls man zwei Y-Achsen benutzt) durch die im Diagrammbaum integrierte Schaltfläche ![]() tauschen.
tauschen.
Die zweite Schaltfläche im Diagrammbaum dient einer Spezialfunktion. Bei zeitanimierten Profilen kann man damit die Datenreihe verdoppeln und bei der ursprünglichen Datenreihe den Zeitpunkt fixieren. Dies vereinfacht die Erstellung von Profilvariantendiagrammen (siehe Beispiel im Abschnitt Extraktoreigenschaften).
5.5. Datenaktualisierung
Das PostProzessing liest die Quelldaten aus den Dateien ein und behält diese Daten im Speicher. Zwischenzeitlich könnten sich die Dateien ändern, z. B. könnte ein Simulationsprogramm Ergebnisse für weitere Zeitpunkte anhängen, oder die Dateien könnten komplett neu geschrieben worden sein. Damit das PostProzessing wieder aktuelle Daten zeigt, kann man alle Diagramme aktualisieren.
Die Aktualisierung erfolgt entweder durch Klick auf das Aktualisierungssymbol ![]() im Diagrammbaum-Fenster.
im Diagrammbaum-Fenster.
Eine Datenaktualisierung kann man auch durch den Menüpunkt: Daten - Diagramm/Daten aktualisieren erzwingen, oder durch Tastaturkurzbefehl F5 bzw. Strg+R (siehe auch Kurzbefehle).
|
Die Aktualisierung wird immer für alle Diagramme und alle darin enthaltenen Datensätze durchgeführt, unabhängig vom aktuell gewählten/aktiven Diagramm. Falls unterschiedliche Diagramme Daten aus den gleichen originalen Datensätzen/Dateien beziehen, so werden die entsprechenden Dateien natürlich nur einmal neu gelesen. |
Je nach Art der dargestellten Daten sieht man sofort einen Einfluss auf die Ergebnisse:
-
Bei 2D-Diagrammen mit Zeitachse und automatischer Achsenskalierung zeigt das Diagramm die kompletten neuen Daten an (eventuell auch weniger als vorher, wenn die Ergebnisdatei neu von vorne geschrieben wurde und nun weniger Datenpunkte enthält)
-
Bei zeitanimierten Farbverlaufsdiagrammen wird normalerweise der letzte Zeitpunkt der neu eingelesenen Datendatei angezeigt, jedoch nur, wenn die Auswahl auf der Zeitskala (im unteren Paneel) auf dem letzten Datenpunkt steht.
Die Menü-Option Daten - Automatische Diagramm/Datenaktualisierung kann ein- und ausgeschaltet werden. Ist sie eingeschaltet, so wird die Aktualisierungsfunktion einmal pro Sekunde ausgeführt.
Manchmal ist es nicht möglich, die Daten zu aktualisieren, z.B. weil die Eingabedatei fehlerhaft ist. Dann werden die im Speicher vorgehaltenen Daten nicht verändert. Eine Fehlermeldung wird im Log-Fenster angezeigt bzw. in die Logdatei geschrieben (siehe Fehleranalyse/Logdatei).
|
Es ist möglich, dass durch fehlerhafte/unpassende Veränderung von Rohdaten eine Aktualisierung der Daten nicht erfolgt, und in den Diagrammen noch alte Daten angezeigt werden. Da diese Daten aber nicht dauerhaft gespeichert werden (die Sitzungsdatei enthält selbst keine Daten), sind die Diagramme beim nächsten Start des Programms bzw. beim nächsten Einladen der Sitzungsdatei leer, obwohl die Daten aktuell noch angezeigt werden. An dieser Stelle hilft es nur, die Datensatzdateien wiederherzustellen oder neu zu erzeugen, z.B. durch erneutes Durchführen der Simulation. |
6. Diagrammfenster
Das oder die Diagrammfenster nehmen den Hauptteil des PostProc 2 Anwendungsfensters ein. Jedes Diagrammfenster hat eine Kopfzeile:

Hat diese einen blauen Hintergrund, so ist dieses Diagramm aktiv. In der Auswahlliste der Diagrammtitelzeile kann das aktuell zu analysierende Diagramm ausgewählt werden. Alternativ dazu kann (wie bereits beschrieben) das aktuelle Diagramm auch über Auswahl im Diagrammbaum eingestellt werden.
6.1. Diagramm- und Tabellenansicht
Die Daten eines Diagramms können auf zwei Arten dargestellt werden. Einmal als graphisches Diagramm, und einmal in einer tabellarischen Datenansicht.
Die Schaltflächen ![]() und
und ![]() im Kopf des Diagrammfensters schalten zwischen Diagrammansicht und Tabellenansicht um. Das Kapitel Tabellenansicht und Dateninterpolation beschreibt die Tabellenansicht im Detail.
im Kopf des Diagrammfensters schalten zwischen Diagrammansicht und Tabellenansicht um. Das Kapitel Tabellenansicht und Dateninterpolation beschreibt die Tabellenansicht im Detail.
6.2. Diagrammteilung
Es ist möglich, das Diagrammfenster zu teilen, sodass zwei oder mehr Diagramme nebeneinander oder untereinander sichtbar sind,
Dieses ist für Variantenanalysen hilfreich, oder wenn Profile von mehr als 2 verschiedenen physikalischen Größen gleichzeitig dargestellt werden sollen. Die Teilung kann auch mehrfach erfolgen, z.B. Temperatur- und Luftfeuchteprofil oben, Dampfdruck- und Flüssigwassergehaltsprofil in der Mitte, Dampf- und Flüssigwasserleitfähigkeiten unten.
Die Teilung erfolgt über die Menübefehle: Chart - Horizontale Teilung etc. und/oder über Kurzbefehle.
Man kann auch die Teilen-Schaltfläche ![]() des Diagrammfensters nutzen, wobei in diesem Fall automatisch eine vertikale oder horizontale Teilung je nach größerer Abmessung gewählt wird.
des Diagrammfensters nutzen, wobei in diesem Fall automatisch eine vertikale oder horizontale Teilung je nach größerer Abmessung gewählt wird.
Ein Diagrammfenster kann man entweder über Menübefehle oder mittels der Schließen-Schaltfläche ![]() wieder verschwinden lassen.
wieder verschwinden lassen.
7. Diagrammformatierung
Die Darstellung der Diagramme und der darin enthaltenen Linien/Farbverläufe kann in den jeweiligen Eigenschaftsfenstern auf der rechten Seite des Bildschirms verändert werden. Nachfolgend sind zunächst die Diagrammoptionen beschrieben, welche für alle Diagrammtypen gleichermaßen gelten.
7.1. Diagrammoptionen
Folgende Eigenschaften können angepasst werden.
| Eigenschaft | Beschreibung |
|---|---|
Name |
Diagrammbezeichner, dient der Verwaltung des Diagramms im Diagrammmanager/Diagrammbaum und in der Auswahlbox im Diagrammfenster (kann Platzhalter enthalten). |
Titel |
Titel, welcher über dem Diagramm angezeigt wird (kann Platzhalter enthalten). Eine leere Zeichenkette entfernt den Titel. |
Schriftart für Titel |
Schriftart und Eigenschaften der Schrift für den Titel
|
Skalen innen zeichnen |
Wenn eingeschaltet, werden die Achsenskalen innerhalb des Diagrammrahmens gezeichnet. |
Globale Schrifteinstellung |
Eine Änderung dieser Schrifteigenschaften wirkt sich auf alle im Diagramm verwendeten Schriften aus und überschreibt eventuell vorher getroffene Schrifteinstellungen. Daher ist es sinnvoll, ganz zuerst die Schrift global zu ändern, und danach die individuellen Einstellungen bei Achsentiteln/Legendeneinträgen etc. vorzunehmen. Konstruktions-/Randlinien (nur bei 4D-Daten) |
7.1.1. Platzhalter/ Textersetzung
Bei Textattributen können je nach Kontext Platzhalter verwendet werden, um automatisch Textbausteine zu ersetzen. Das ist z. B. bei Serien- und Achsentiteln sinnvoll. Derzeit werden folgende Platzhalter unterstützt, wobei aber nicht alle Platzhalter überall ersetzt werden (können), siehe Beschreibung.
| Platzhalter | Ersetzungstext |
|---|---|
|
Physikalische Werteeinheit, sinnvoll bei Achsentitel |
|
Vollständiger Pfad zur Datendatei, aus der die Serie stammt |
|
Der Dateiname der Datendatei, aus der die Serie stammt. Bei DELPHIN Ausgaben wird zusätzlich der Basis-Verzeichnisname vorangestellt, also bei einer Datendatei |
|
Dateiname der Datendateie ohne Pfad und Erweiterung |
|
Physikalische Größe (z. B. Temperature oder Moisture mass density) |
|
Aktuelles Datum (nur im Diagrammtitel) im Format 27.02.2003 |
|
Aktuell ausgewählter Zeitpunkt bei zeitabhängigen Datensätzen, dargestellt als Zeitabstand zum Startzeitpunkt |
|
wie ACHTUNG: auf die verschachtelten Klammern |
|
wie |
|
|
7.2. Extraktoreigenschaften
Hier werden Schnittkoordinaten/-zeitpunkte einer Datenreihe festgelegt. Dies betrifft 2D Diagrammserien (Datenreihen), welche aus 3D/4D oder 5D-Daten herausgeschnitten werden, oder 3D Diagrammdaten, welche aus 4D oder 5D-Datensätzen extrahiert werden.
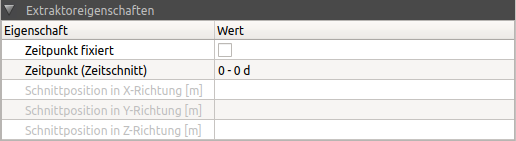
Je nach Schnitt-Typ (TimeCut, XCut, YCut, ZCut) können für jeden dieser Datensätze getrennt verschiedene Zeitpunkte oder Schnittflächen festgelegt werden. Im Beispielbild oben wird ein Zeitschnitt verwendet. Zeitpunkte werden üblicherweise über die Animationsschaltflächen im unteren Paneel verändert/festgelegt. Es ist aber auch möglich, den Zeitpunkt in dieser Registerkarte einzutragen und auch zu fixieren, sodass bei Änderung des Animationszeitpunktes der Zeitpunkt dieser Datenreihe unverändert bleibt.
|
Durch Fixieren des Zeitpunkts bei zeitanimierten Profillinien lassen sich im gleichen Diagramm die Profile zu verschiedenen Zeitpunkten darstellen. Dazu wird die gleiche Datenreihe mehrfach hinzugefügt und in den Extraktoreigenschaften verschiedene Zeitpunkte eingestellt und fixiert. 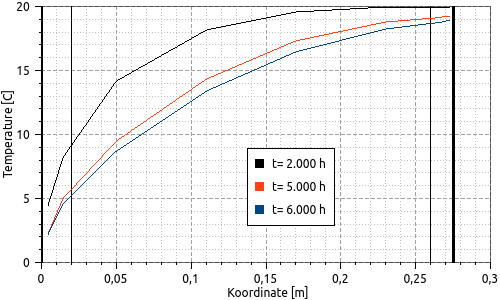
Abbildung 33. Profilschnittdiagramm mit mehreren Datensätzen, mit verschiedenen fixierten Zeitpunkten
Das Erstellen solcher Diagramme wird durch die Schaltfläche |
7.3. Achsendarstellung
Das Eigenschaftsfenster für die Achsen enthält oben eine Auswahlliste, in der die zu bearbeitende Achse ausgewählt werden kann. Je nach Achse und Diagrammtyp werden unterschiedliche Einstellungen angeboten. Nur die untere Achse kann als Datums-/Zeitachse konfiguriert werden.
Die meisten Achseneigenschaften sind selbsterklärend. Für einige Einstellungen sind nachfolgend spezielle Informationen gegeben:
| Eigenschaft | Beschreibung |
|---|---|
Skalierung |
Schaltet die Achsenskala zwischen linearer und logarithmischer Darstellung um. Datenreihen sollten bei logarithmischen Darstellungen keine 0-Werte enthalten. Die logarithmische Darstellung wird durch geeignete Wahl der Gitterlinien verstärkt. |
Einheit |
Einheit, welche an der Achse angezeigt werden soll. Eine Änderung der Einheit bewirkt ein Umrechnen der Achsenskalen auf die neue Einheit. Der Einheitenname wird im Platzhalter |
Datums-/Zeitachse |
Wenn aktiviert, wird anstelle der Zeitabstände ein konkretes Datum angezeigt. Die Art der Anzeige wird über die Datum/Zeit-Formate definiert. Bei automatischer Achsenskalierung wird der Skalenbereich je nach Auflösung auf gerade Zeitabstände angepasst. |
Null-Zeitpunkt für Datumsachse |
Die Datensätze enthalten üblicherweise Daten als Zeitabstand zu einem gewählten Referenzzeitpunkt. Diese Eigenschaft erlaubt die Definition dieses Zeitpunkts. |
Datum/Zeit-Formate |
Je nach Zoomstufe bzw. angezeigtem Zeitbereich wird eine andere Achsenbeschriftung verwendet. Diese Beschriftungstexte können hier angepasst werden. Dabei werden die Datums-/Zeitelemente entsprechend einer Formatdefinition übertragen. Unterstützt werden folgende Formatkürzel zur Definition von Zeitformaten: zzz (für Millisekunden), ss, mm, hh (Sekunde, Minute, Stunde), dd (Tag als Zahl), ddd (Tag als Tag der Woche), MM, MMM, MMMM (für Monate), ww (für Wochennummer), yy und yyyy (für Jahreszahlen). Ein typisches Datums-Zeitformat wäre für die Stunden-Zoomstufe: |
Titel |
Achsentitel, kann Platzhalter enthalten. Ein leerer Text entfernt den Achsentitel. Mehrzeilige Beschriftungstexte können erstellt werden, wenn |
Gitterlinientyp und Farbe |
Hier kann man das Erscheinungsbild des Gitterrasters festlegen. Das Haupt- und Nebengitter kann zwar für die X-Achse und die linke Y-Achse getrennt ein- und ausgeschaltet werden, es gibt jedoch nur eine Linien- und Farbeinstellung für jeweils das Haupt- und Nebengitter. |
Titelabstand |
Eigentlich der Abstand der Achsenskalenlinie vom Diagrammrand und damit im Falle eines angezeigten Titels auch der Abstand des Titels von der Achse. |
|
Die Einstellung zum Titelabstand kann genutzt werden, um bei untereinander oder nebeneinander ausgerichteten Diagrammen (wenn diese nach dem Diagrammexport in einem Dokument eingefügt werden) eine einheitliche Größe und einheitliche Abstände einzustellen. Bei gleichem Titelabstand, z. B. bei der linken Achse, sind bei untereinander angeordneten Diagrammen auch die Achsenlinien exakt untereinander ausgerichtet, unabhängig von der Länge der Achsenlabels/Beschriftung. |
7.4. Liniendiagramme
In Liniendiagrammen können die einzelnen Linien und die Legende formatiert werden.
7.4.1. Legendeneinstellungen
Liniendiagramme enthalten eine Legende zur Identifikation der einzelnen Linien mit folgenden Einstellungsmöglichkeiten:
Die Legende kann innerhalb des Diagramms oder außerhalb platziert werden (Eigenschaft Position). Innen liegende Legenden sind immer an einem Rand oder einer Ecke verankert (Eigenschaft Ausrichtung). Der Abstand vom jeweiligen Rand wird über die gleichnamige Eigenschaft kontrolliert. Wird das Diagramm vergrößert oder verkleinert, z. B. beim Diagrammexport, bleibt die Legende in Bezug auf den Ankerpunkt positioniert.
|
Eine innen liegende Legende lässt sich mit der Maus an eine beliebige Stelle ziehen (Drag&Drop). Dabei wird je nach Ablageplatz die nächstliegende Ankerposition gewählt und der Abstand berechnet. |
Nachfolgend ein Beispiel für eine innen liegende, rechts-unten verankerte Legende bei verschiedenen Diagrammgrößen:
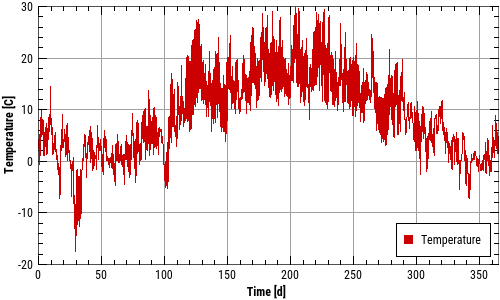
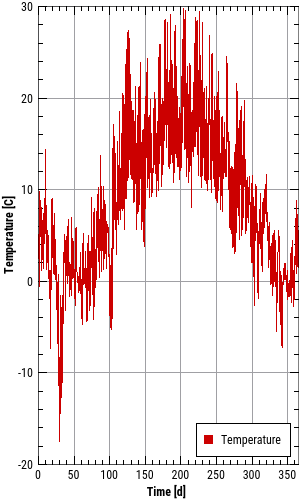
Die Eigenschaften Rahmen, Hintergrundfarbe und Transparenz gelten nur für innen liegende Legenden.
Der Icon-Stil definiert, ob Linienart und Symbol in der Legende gezeigt werden sollen, oder nur ein farbiges Rechteck. Letzteres ist die Voreinstellung, da Diagramme standardmäßig mit durchgezogenen Linien gleicher Stärke und ohne Symbol erstellt werden:
Die Breite der Linie bei der Liniensymboldarstellung kann über die Eigenschaft Icon-Breite konfiguriert werden.
Sind sehr viele Linien darzustellen, kann man die Anzahl der Legendeneinträge nebeneinander über die Eigenschaft Maximale Anzahl der Spalten wählen. Eine 0 bedeutet, dass je nach Diagrammbreite automatisch eine geeignete Spaltenanzahl bestimmt wird.
|
Die automatische Bestimmung der Spaltenanzahl in der Legende funktioniert nicht bei einer innen liegenden Legende, da hier keine Information über die zulässige Breite vorhanden ist. Wird die Plotfläche kleiner als die Legende, so wird diese links bzw. rechts oder oben/unten entsprechend abgeschnitten. Bei innen liegenden Legenden sollte man also immer die maximale Spaltenanzahl festlegen. |
7.4.2. Formatierung der Linien
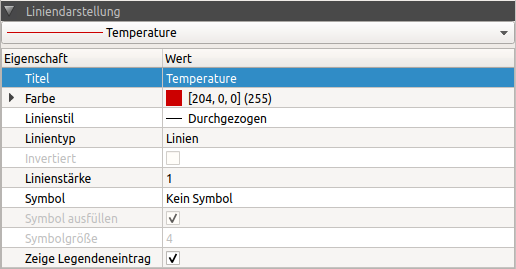
Das Eigenschaftsfenster für Linienattribute hat eine Auswahlliste, in der die aktuelle Linie ausgewählt werden kann. Die Auswahl entspricht der Hervorhebung/Markierung im Diagrammverwaltungsbaum.
Die Attribute für die Linien entsprechen den üblichen Einstellungen für Linien in Liniendiagrammen.
|
Die Linienfarbe und Symbolfarbe ist bei einer Datenreihe/Linie immer gleich. Möchte man verschiedenfarbige Linien- und Symbolfarben haben, so kann man die Datenreihe ein zweites Mal einfügen, und einmal als Linie und einmal als Symbol (ohne Linie) formatieren. Damit der Datensatz dann nicht zweimal in der Legende erscheint, kann man die Eigenschaft Zeige Legendeneintrag bei einer Datenreihe ausschalten. |
Die folgenden Eigenschaften haben eine besondere Bedeutung:
| Eigenschaft | Beschreibung |
|---|---|
Linientyp |
Definiert die Art, wie die X-Y-Datenwerte interpretiert und dargestellt werden sollen: Linien: normale Linien, bei denen die einzelnen Datenpunkte durch Linien verbunden werden (sinnvoll für lineare Verläufe zwischen Stützstellen) Stäbe: Vertikale Linien zwischen Datenpunkten und der X-Koordinatenachse Stufen: zwischen einzelnen Datenpunkten (d.h. im Intervall zwischen zwei Stützstellen) werden die Verläufe als konstant angenommen. Das zusätzliche Attribut Invertiert bestimmt, ob der Wert zu Beginn des Intervalls oder der vom Ende des Intervalls verwendet werden soll. Dies ist sinnvoll, wenn z.B. sich sprungartig ändernde Werte (Kontrollparameter, z. B. Solltemperaturen) dargestellt werden sollen. Punkte: an jedem gegebenen Datenpunkt wird ein ausgefüllter Kreis im Diagramm gezeichnet. Die Linienstärke definiert hier den Durchmesser des Kreises. Sollen stattdessen andere Symbole gezeichnet werden, sollte der Linienstil auf Keine Linie gestellt werden und dann ein Symbol ausgewählt werden. |
Invertiert |
Siehe Linientyp Stufen |
Zeige Legendeneintrag |
Ist diese Eigenschaft deaktiviert, wird für die aktuelle Linie kein Legendeneintrag angezeigt. Dies ist auch sinnvoll, wenn man bei einer Linie z.B. obere und untere Grenzen als Symbole anzeigen möchte, und dies mit zusätzlichen Datenreihen macht (welche dann natürlich nicht in der Legende erscheinen sollen). |
|
Wird die Eigenschaft Zeige Legendeneintrag wieder eingeschaltet, so erscheint der Legendeneintrag am Ende der Legende. Das ist unabhängig von der Zeichenreihenfolge, d.h. Reihenfolge, in der die Serien/Linien dem Diagramm hinzugefügt wurden. So können Legendeneinträge auch beliebig umsortiert werden. Allerdings wird das nicht abgespeichert und beim nächsten Laden der Sitzung ist die ursprüngliche Reihenfolge wiederhergestellt. |
7.5. Farbverlaufsdiagramme
Es gibt zwei Arten von Farbverlaufsdiagrammen:
-
Zeitverlaufsdiagramme, bei denen die X-Achse die Zeitachse ist und der zeitliche Verlauf einer 1D-Profilkurve zu sehen ist, und
-
Profil- bzw. Felddiagramme, bei denen die Werteverteilung über eine 2D-Geometrie für jeweils einen Zeitpunkt dargestellt ist.
Letztere sind immer zeitanimierte Diagramme (siehe Diagrammanimation).
Bei Farbverlaufsdiagrammen wird rechtsseitig immer eine Farblegende angezeigt. Diese wird hinsichtlich des Erscheinungsbildes wie andere Achsen auch im Achseneigenschaftsfenster konfiguriert (rechte Achse). Alle Eigenschaften, welche die Farbtabelle betreffen, werden jedoch im Eigenschaftsfenster für die Farbtabelle definiert.
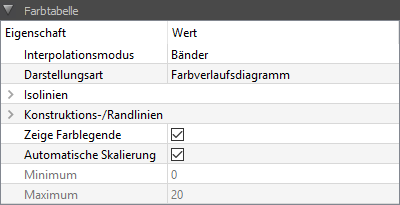
Der Interpolationsmodus beeinflusst die Art, wie (Farb-)werte innerhalb von Gitterelementen berechnet werden. Bei den vom PostProzessing unterstützten volumen-/elementzentrischen Daten werden die einzelnen Werte für den Mittelpunkt eines Gitterelements definiert. Es gibt nun verschiedene Optionen, diese Daten darzustellen. Um einen weichen Verlauf zwischen diesen Einzelwerten zu zeichnen, werden zunächst für die Knoten (d. h. Gittereckpunkte) Werte durch gewichtete Interpolation berechnet. Dann können die Farbwerte innerhalb eines Gitterelements durch Wichtung der Eckwerte (lineare Interpolation) bestimmt werden.
Für die Eigenschaft Interpolationsmodus gibt es 3 Optionen:
-
Rohdaten: Diese Darstellung zeigt die tatsächlich im Simulationsprogramm berechneten Werte an, d. h. es findet keine Interpolation statt. Große Unterschiede zwischen benachbarten Elementen können auf zu grobe Gitter hindeuten, daher ist diese Darstellung insbesondere für Gittersensitivitätsstudien/Genauigkeitskontrolle hilfreich .
-
Bänder: Die durch Interpolation berechneten Werte werden den definierten Farbbändern (siehe auch Farbtabelle) durch abrunden zugeordnet. Gibt es beispielsweise Farbwertzuordnungen für 20, 16, 12, … °C, und die berechneten Temperaturen sind 19.2°C oder 17.3°C, so werden diese auf 16°C abgerundet und damit in der Farbe des 16°C-Bandes gezeichnet. Diese Darstellung ist am besten geeignet, schnell einen Überblick über die Verteilung und Gradienten der Werte zu erhalten.
-
Interpoliert: Die durch Interpolation berechneten Werte werden direkt auf einen Farbwert abgebildet, wobei wiederum zwischen Farbtabellenwerten interpoliert wird. Gibt es beispielsweise Farbwertzuordnungen für 20, 16, 12, … °C, und eine berechnete (bzw. aus Eckwerten interpolierte) Temperatur ist 19.2°C, so wird die zu zeichnende Farbe aus der Interpolation zwischen den Farbwerten für 20 und 16°C bestimmt. Für 19.2°C wird also der Farbwert von 20°C entsprechend stärker gewichtet als der von 16°C.
Bei Farbverlaufsdiagrammen können zusätzlich noch Isolinien eingezeichnet werden, d. h. Kurven, welche entlang der Niveaulinien z. B. Linien gleicher Temperatur verlaufen. Die Eigenschaft Darstellungsart erlaubt die Auswahl zwischen, Farbverlaufsdiagramm oder Farbverlaufsdiagramm mit Isolinien. Es ist auch möglich, ausschließlich Isolinien zu zeichnen, was für schwarz-weiß Publikationen nützlich sein kann.
Weitere Eigenschaften sind:
| Eigenschaft | Beschreibung |
|---|---|
Isolinien |
Erlaubt die nähere Definition von Isolinien durch zahlreiche Untereigenschaften. Dabei bestimmt die Untereigenschaft |
Konstruktions-/Randlinien |
In 2D-Geometriedetails gibt es häufig Materialgrenzen und Konstruktionsränder. Die Art und Weise, wie diese Linien gezeichnet werden, wird durch diese Eigenschaft konfiguriert. |
Zeige Farblegende |
Schaltet die rechte Achse mit der Farblegende sichtbar oder unsichtbar. |
Automatische Skalierung |
Ist diese eingeschaltet, so werden die Wertebereichsgrenzen automatisch aus dem aktuell angezeigtem Datensatz bestimmt. |
7.5.1. Automatische Skalierung und globale Minima und Maxima
Bei zeitanimierten Farbtabellen werden jeweils immer nur die Daten eines Zeitpunkts angezeigt. Die je Zeitpunkt berechneten Werte können sich jedoch im Verlauf der Zeit drastisch ändern, d. h. die aktuellen Minimal- und Maximalwerte sind in der Regel von den globalen Minimal- und Maximalwerten (aller Daten) verschieden.
Die Eigenschaft Automatische Skalierung verwendet, falls eingeschaltet, zur Berechnung der Maximal-/Minimalwerte immer nur die Zahlenwerte des aktuell angezeigten Zeitpunkts.
Die Schaltfläche Berechne globale min-/max-Werte durchläuft hingegen den gesamten Datensatz und trägt das Maximum und das Minimum als Wertebereichsgrenzen ein.
|
Bei zeitanimierten Diagrammen liest das PostProzessing aus Performancegründen nur tatsächlich verwendete Zeitpunkte/Zeitbereiche ein (was gerade bei binären Datenkontainer sehr schnell geht). Für die Bestimmung der globalen Maxima und Minima muss jedoch die komplette Datei in den Speicher gelesen werden, welches je nach Festplattengeschwindigkeit einiges an Zeit dauern kann und zudem den Hauptspeicher befüllt. Daher gibt es auch keine Option, diese automatische Min-/Max-Berechnung bei jeder Änderung der Datei durchzuführen. |
7.5.2. Definition der Farbtabelle
Farbtabellen sind immer relativ definiert und werden dann auf den Wertebereich angewendet. Wenn also, wie im folgenden Beispielscreenshot, 10 Farbintervalle definiert sind, entspricht der oberste Farbwert immer dem maximalen Zahlenwert, während der unterste Farbwert immer dem minimalen Farbwert entspricht. Die Farben dazwischen sind in gleichen Abständen definiert.
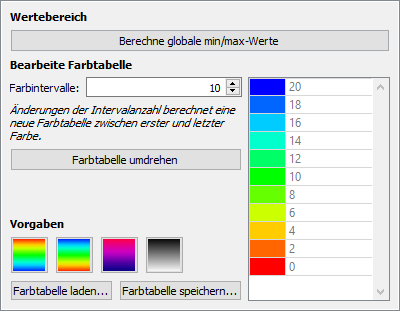
Die Anzahl der Farbintervalle hat primär eine Auswirkung auf die Bänder-Darstellung und die Isolinien. Nachfolgende Screenshots zeigen den Unterschied zwischen 10 und 20 Farbintervallen. Bei sehr vielen Farbbändern nähert sich die Darstellung dem Interpoliert-Modus an (siehe Beschreibung zur Eigenschaft Interpolationsmodus oben).
Die Farben der Farbtabelle lassen sich auch individuell ändern. Durch Doppelklick auf die einzelnen Farben öffnet sich ein Farbwahldialog. So lassen sich z. B. auch kritische Wertebereiche hervorheben:
Komplett neue Farbübergänge lassen sich erzeugen, wenn man zuerst die oberste und unterste Farbe auswählt, und danach die Anzahl der Farbintervalle ändert. Dabei werden die dazwischenliegenden Farben basierend auf dem Farbrad neu berechnet.
Einmal bestimmte Farbtabellen lassen sich in *.p2colormap-Dateien abspeichern und wieder einladen (mit den entsprechend benannten Schaltflächen). Diese Dateien haben ein einfaches XML-Format und können auch extern generiert werden.
8. Speichern und Anwenden von gespeicherten Diagrammstilen
Wenn man mehrere Diagramme mit gleichem Erscheinungsbild konfigurieren will, so kann man zunächst das Format eines Diagramms abspeichern und dieses dann später komplett oder teilweise auf andere Diagramme anwenden.
8.1. Speichern von Diagrammstilen
Der Menübefehl Chart - Speichere aktuelles Diagrammformat... öffnet einen Dialog zur Eingabe eines eindeutigen Namens für das zu speichernde Diagrammformat. Das Diagrammformat wird in einer Datei gespeichert, und der eingegebene Name wird für die zu erstellende Diagrammdatei als Dateiname verwendet.
Diagrammformatdateien werden im Benutzerdatenverzeichnis, im Unterverzeichnis styles abgelegt.
Nach Bestätigung des Dialogs wird das Format des aktuell ausgewählten Diagramms in die Datei geschrieben. Danach erscheint der Diagrammformat-Name im Menü: Chart - Wende gespeichertes Diagrammformat an.
8.1.1. Vordefinierte Linienstile in Format/Diagrammstil-Dateien
In einer Diagrammformatdatei werden immer genauso viele Diagrammstile gespeichert, wie im originalen Diagramm vorhanden waren. Wird eine solche Formatdatei auf ein Diagramm mit mehr Linien angewendet, so werden nur die gespeicherten Diagrammformate übertragen, die anderen Linien erhalten Standardeinstellungen (Farben, Linienstärken etc.). Hat das Zieldiagramm weniger Linien, so werden nur die Formate für die vorhandenen Linien übertragen.
8.2. Anwenden eines gespeicherten Formats
Beim Programmstart werden die Verzeichnisse für Diagrammstile durchsucht und die Namen der Dateien (ohne Endung) im Menü Chart - Wende gespeichertes Diagrammformat an angezeigt.
Eingebaute Diagrammstile werden im Installationsverzeichnis, d.h. {Installationsverzeichnis}/resources/styles gesucht, benutzerdefinierte Diagrammformatdateien im Verzeichnis {PostProcApp-Anwenderdaten}/styles (siehe Benutzerdatenverzeichnis). Diagrammformatdateien haben die Endung p2style.
|
Existiert im anwenderspezifischen Vorlagenverzeichnis eine Datei mit gleichem Namen wie eine eingebaute Stildatei, so wird nur die Datei im Anwenderverzeichnis im Menü angezeigt. |
Sobald ein Diagrammformat im Menü ausgewählt wurde, öffnet sich ein Dialog mit Auswahlmöglichkeiten. Hier können die einzelnen zu übertragenden Formatkomponenten ausgewählt werden. Nach Bestätigung des Dialogs werden die Änderungen auf das aktuell gewählte Diagramm angewendet.
8.3. Anwenden des zuletzt benutzten Formats
Sobald einmal ein Diagrammformat angewendet wurde, wird der Name dieser Datei vermerkt. Danach kann dieses Format schnell wieder erneut ausgewählt werden, entweder durch den Menübefehl Chart - Wende Diagrammformat '<name>' an oder durch den Kurzbefehl Strg + F. So lässt sich ein Format schnell auf neu erstellte Diagramme anwenden.
Das Programm merkt sich diese Formatdatei, solange die Datei existiert und kein anderes Format ausgewählt und angewendet wurde.
|
Der Kurzbefehl |
8.4. Bearbeiten, Umbenennen und Löschen eines Diagrammstils bzw. einer Diagrammformatdatei
Diagrammformatdateien enthalten einen Ausschnitt aus einer PostProc-Sitzungsdatei. Daher können diese auch manuell erstellt werden bzw. mit dem Texteditor bearbeitet werden. Auch können die Formatdateien *.p2style einfach umbenannt oder gelöscht werden. Beim nächsten Programmstart wird das Menü mit den verfügbaren Diagrammstilen aktualisiert.
9. Diagrammanimation
Diagramme, bei denen aus den Ausgangsdaten Zeitscheiben ausgeschnitten werden (TimeCuts), können zeitlich animiert werden. Das sind zum Beispiel Farbverlaufsdiagramme von 2D-Geometrien, wobei jeweils der Farbverlauf nur für einen Zeitpunkt angezeigt wird. Oder Liniendiagramme aus 1D-Geometrien, welche als zeitlich animierbare Profile dargestellt werden.
Mit Zeitanimation wird zunächst nur die recht komfortable Einstellung/Änderung des aktuellen Zeitpunktes bezeichnet. Dazu ist im unteren Panell ein Schieberegler, mit dem man den atuellen Zeitpunkt flexibel verschieben kann. Auch kann man über die Animationsschaltflächen die zeitliche Veränderung wie einen Film steuern (und mit dem kleinen Schieberegler ganz rechts die Geschwindigkeit einstellen). Weiterhin kann man den gewünschten Zeitpunkt auch direkt als Zahl eingeben.
Im unteren Paneel werden auf der linken Seite alle zeitlich animierbaren Diagramme d. h. Diagramme ohne Zeitachse aufgeführt. Sobald mindestens ein Diagramm markiert ist, werden die im Datensatz verfügbaren Zeitpunkte in der Skala rechts dargestellt und die Animationsschaltflächen sind aktiv. Sobald der aktuelle Zeitpunkt verändert wird, werden alle Diagramme entsprechend aktualisiert.
|
Falls der Zeitpunkt einer Datenreihe in den Extraktoreigenschaften fixiert ist, so verändert sich der Datensatz auch bei Veränderung des Schiebereglers nicht mehr. |
9.1. Gleichzeitige Animation mehrerer Datensätze
Falls mehrere Datensätze gleichzeitig markiert sind, werden alle markierten Datensätze auch gleichzeitig animiert. Die Zeitskala zeigt hierbei die Gesamtheit aller in den verschiedenen Datensätzen vorhandenen Zeitpunkte an. Enthält z.B. ein Datensatz Tageswerte, der zweite jedoch Stundenwerte, so werden Stundenwerte angezeigt. Die Einheit lässt sich jedoch ändern. Bei Auswahl eines Zeitpunkts wird im jeweiligen Datensatz wenn vorhanden entweder genau der ausgewählte Zeitpunkt verwendet, oder der nächste zeitigere Zeitpunkt. Es findet keine Interpolation statt.
Es werden beispielsweise 2 Datensätze dargestellt, der eine hat die Zeitpunkt 0 12 24 jeweils in Stunden angegeben, während der andere Datensatz 0 1 2 in Tagen hat. Bei der Zusammenstellung der Zeitanimationsskale werden nun zunächst die Zeitpunkte in die gleiche Einheit umgerechnet und zusammengeführt, also ergibt sich 0 12 24 48 in h. Bei der Umrechnung von Zeitpunkt können auch Rundungsfehler auftreten, welche dann zu einer gemeinschaftlichen Zeitachse wie 0 12 24 24.000001 48 führen könnten.
Wählt man nun z.B. den Zeitpunkt 12 h mit dem Schieberegler aus, wird im ersten Datensatz dieser Zeitpunkt gewählt, im 2. Datensatz existiert dieser Zeitpunkt jedoch nicht. Deshalb wird der Zeitpunkt 0 d im 2. Datensatz angezeigt.
Bei der Datenaktualisierung wird auch die Zeitskale angepasst, wenn z. B. durch Fortschreiten der Simulation neue Zeitpunkte in einer Datenreihe hinzugekommen sind. Dabei gibt es folgende Regeln:
-
ist vorher der letzte Zeitpunkt ausgewählt (Schieberegler ganz rechts), so wird nach dem Aktualisieren mit Hinzufügen neuer Datenreihen der Schieberegler automatisch auch wieder auf den letzten Zeitpunkt gesetzt. Somit wird beim Aktualisieren immer das letzte Profil angezeigt - praktisch, um den Simulationsfortschritt zu beobachten.
-
ist vor der Aktualisierung ein anderer Zeitpunkt als der letzte ausgewählt, so bleibt diese Einstellung. So bleibt bei bestimmter Auswahl eines Zeitpunkts das Diagramm auch bei einer Datenaktualisierung unverändert. Falls dieser Zeitpunkt nach der Aktualisierung nicht mehr existiert, wird der nächstegelegene Zeitpunkt ausgewählt.
10. Tabellenansicht und Dateninterpolation
Schaltet man in die Tabellenansicht um (siehe Diagramm- und Tabellenansicht) so werden die im Diagramm angezeigten Daten in einer Tabelle als Zahlen angezeigt. So kann man konkrete Werte ablesen oder die Daten einfach in eine andere Anwendung exportieren.
10.1. Datenexport
Die angezeigten Daten lassen sich in die Zwischenablage kopieren. Die kopierte Tabelle lässt sich dann direkt in ein Tabellenkalkulationsprogramme (Excel, LibreOffice,…) einfügen. Die Daten werden als durch Tabulatoren getrennte Spalten kopiert (entsprechend dem TSV-Format, siehe TSV-Dateien), welches von PostProc eingelesen werden kann.
Die Auswahl der Daten bzw. Markieren der Zellen erfolgt wie in jedem üblichen Tabellenkalkulationsprogramm wie Excel/LibreOffice etc.
Im Tabelleneigenschaftsfenster rechts kann hierbei ausgewählt werden, ob nur die aktuelle Auswahl oder die gesamte Tabelle kopiert werden soll.
|
Die Schaltfläche Kopiere alles in die Zwischenablage ist letztlich nur eine Bequemlichkeitsfunktion. Man kann auch mit |
Es stehen folgende Optionen zur Verfügung, die den Export beeinflussen:
10.1.1. "Kopiere Kopfzeilen"
Bei 2D-Diagrammen werden die Zeilenüberschriften kopiert, sodass beispielsweise eine generierte Datei wie folgt aussieht:
Time [h] Var1.Temperatur [C] Var2.Temperatur [C] 0 10 10 1 12 11.5 2 16 13 ...
Ist die Option ausgeschaltet, werden nur die eigentlichen Daten kopiert.
Bei 3D-Diagrammen werden bei eingeschalteter Option die Koordinaten in den Überschriften in die oberen Zeilen und die linke Spalte kopiert.
10.1.2. "Einheiten auf separater Zeile"
Bewirkt den Export im Format. Dies ist eigentlich nur sinnvoll, wenn die Zeilenüberschriften sehr lang sind und die Einheit dann in der Zielanwendung abgeschnitten/nicht sichtbar ist.
Time Var1.Temperatur Var2.Temperatur [h] [C] [C] 0 10 10 1 12 11.5 2 16 13 ...
|
Dieses Format wird vom PostProc 2 nicht unterstützt, siehe auch Formatspezifikation im Abschnitt TSV-Dateien. |
10.1.3. "Verwende , statt . als Dezimaltrennzeichen"
Dadurch kann zwischen deutschem und englischem Zahlenformat unterschieden werden. Hilfreich beim Export nach Excel/LibreOffice (welches deutsches Zahlenformat verlangt) und in Textdateien zur Weiterverwendung in anderen Tools, wobei englisches Zahlenformat verlangt wird.
10.2. Datenfiltern und Interpolation
Wenn Zeitreihen mit unterschiedlichen Zeitpunkten zusammen in einer Tabelle dargestellt werden, so werden die jeweils fehlenden Werte linear zwischen den benachbarten Stützstellen interpoliert (welches der grafischen Darstellung bei Liniendarstellung entspricht). Zur Unterscheidung von tatsächlich im Datensatz enthaltenen Werten werden interpolierte Werte eingefärbt:
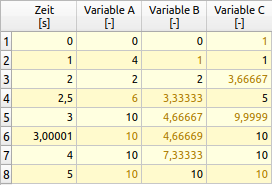
Die Interpolation ist vor allem dann hilfreich, wenn man nach dem Export in eine Tabellenkalkulation noch weitere Berechnungen (Differenzenbildung, etc.) mit den Datenreihen durchführen möchte.
Nachfolgend werden die dafür verwendeten Regeln erläutert.
Folgende Datensätze sind im obigen Beispiel verwendet:
Time [s] Variable A [-] 0 0 1 4 2 2 3 10 4 10
Time [s] Variable B [-] 0 0 2 2 5 10
Time [s] Variable C [-] 1.00000000001 1 2.5 5 3.00001 10 4 10
Diese Datensätze enthalten unterschiedliche Zeitreihen. In Datensatz C ist die Situation nachgestellt, die bei numerischen Simulationen gelegentlich vorkommt, d.h. durch Rundungsfehler bei Gleitzahlenberechnungen ist der Zeitpunkt 1 mitunter nicht exakt 1 sondern minimal größer oder kleiner, in diesem Fall 1.00000000001.
Bei der Weiterverarbeitung der Daten sollen diese Zeitpunkte dennoch identisch behandelt werden, weswegen alle Zeitpunkt mit relativem Abstand kleiner als 1e-9 als gleich betrachtet werden.
|
Die genaue Formel lautet: TOLERANCE = |t_i|*1e-9 + 1e-7 Zeitpunkte werden als unterschiedlich betrachtet, wenn t_{i-1} + TOLERANCE > {t_i}
ist. |
Im Fall der Zeitpunkte 3 und 3.00001 ist der Abstand größer und die Zeitpunkte erscheinen individuell aufgeführt in der Tabelle.
|
In der Zeitspalte werden die Zeitpunkte aller Datenreihen sortiert angezeigt. Bei den Datensätzen, bei denen diese Zeitpunkt nicht existieren, werden die Zeitpunkte approximiert, entsprechend nachfolgend beschriebener Regeln. So berechnete Werte werden zur Unterscheidung eingefärbt (siehe Screenshot oben). |
10.2.1. Interpolation von Zwischenwerten
Sind Werte in einem Datensatz nicht vorhanden, werden diese linear interpoliert. So ergibt sich z.B. für Datensatz B für t=1 den interpolierten Wert 1.
10.2.2. Extrapolation
Fehlen Werte am Anfang oder Ende werden diese konstant vom nächsten bzw. vorherigen Wert extrapoliert. Zum Beispiel enthält der Datensatz C weder Werte für den Zeitpunkt 0 noch für den letzten Zeitpunkt 5. Für den Zeitpunkt 0 wird deshalb der erste verfügbare Wert (vom Zeitpunkt 1) angezeigt. Und für den Zeitpunkt 5 der letzte (vom Zeitpunkt 4).
10.3. Zeitpunkte filtern
Für die Analyse ist es manchmal notwendig, dass die Zeitpunkte einer Zeitreihe als Referenz gelten (z. B. Stundenwerte) und dazwischenliegende Zeitpunkte aus anderen Zeitreihen nicht verwendet werden. In diesem Fall können die Zeitpunkte eines Datensatzes als Filter ausgewählt werden.
Das Filtern wird über die Auswahlbox Zeige Zeitpunkte des Extraktors/der Spalte eingeschaltet. Danach wird die Spaltennummer ausgewählt, die dem Datensatz entspricht (Nummerierung beginnt mit 1 beim ersten Datensatz nach der Zeitspalte). Wird beispielsweise die Datenspalte 1 (Datensatz A) ausgewählt, so erscheinen nur noch die Zeitpunkte dieses Datensatzes in der Tabelle:
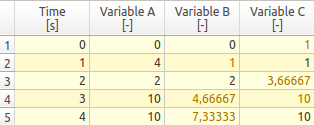
10.4. Zeiteinheit anpassen
Die Zeitspalte in der Tabellenansicht zeigt normalerweise die gleiche Einheit an, wie sie für die X-Achse im Diagramm verwendet wird. Möchte man beim Datenexport oder zum Suchen eines bestimmten Zeitpunktes eine andere Zeiteinheit verwenden, so kann man das in der Auswahlliste einstellen.

|
Wenn die Standardeinheit für die Anzeige verwendet wird, dann werden die Zahlen mit Standardwerteformatierung angezeigt, d.h. üblicherweise mit 6 Stellen Genauigkeit. Wählt man jedoch eine Zeiteinheit aus der Auswahlliste aus, dann wird eine für diese Zeiteinheit typische Zahlenformatierung gewählt. |
|
Wenn die Zeitpunkte mit Datums-/Zeitstempeln angezeigt werden, ist die Basiseinheit ms (Millisekunden), da intern Zeitpunkt in Millisekunden seit dem Referenzjahr verwaltet werden. |
11. Modelle - Schadensprognose
Im PostProc 2 existiert die Möglichkeit, Modelle auf ausgewählte Daten anzuwenden. Dies ist aktuell für 2D-Daten in Form von Zeitreihen möglich. Die Auswahl der Modelle erfolgt mittels einer Liste im unteren Teil des Hauptfensters der Datenverwaltungsansicht (siehe [3] in Abbildung 2D-Diagramm-Konfigurationsfenster).
Damit ein Modell ausgewählt werden kann, muss exakt ein 2D-Datensatz mit Temperaturwerten und ein 2D-Datensatz mit Daten der relativen Luftfeuchte ausgewählt sein. Eine Modellauswahl ist nur möglich, wenn genau diese zwei Datensätze ausgewählt sind.
In der aktuellen Version von PostProc 2 sind folgende Modelle implementiert und können in der Auswahlliste gewählt werden:
-
Isoplethenmodell
-
VTT Schimmel-Modelle
-
WTA Holzzerstörungsmodell
-
VTT Holzzerstörungsmodell
-
Algenwachstumsmodell für Mauerziegel
Ein Klick auf die Schaltfläche Diagramm erstellen erstellt ein Diagramm entsprechend des ausgewählten Typs mit den Basiseinstellungen. Wenn Kein Modell gewählt ist, wird ein Liniendiagramm mit den beiden ausgewählten Datensätzen erzeugt (siehe Abschnitt 2D Diagramme).
Die Datensätze müssen für die Verwendung in Modellen nicht zwingend die gleiche Zeiteinheit und die gleiche Schrittweite haben. Empfohlen werden aber Stundenwerte.
11.1. Isoplethenmodell
Das Isoplethenmodell dient zur Abschätzung des Risikos des Schimmelwachstums auf frei bewitterten Oberflächen. Genaueres zu diesem Modell findet sich im
WTA Merkblatt 6.3
sowie in
Sedlbauer, K. : Beurteilung von Schimmelpilzbildung auf und in Bauteilen. Dissertation Universität Stuttgart (2001).
Bei diesem Modell wird die relative Luftfeuchte (y-Werte) gegen die Temperatur (x-Werte) zum gleichen Zeitpunkt dargestellt. Direkt nach dem Erstellen wird ein Diagramm wie im folgenden Bild dargestellt.
Man kann nun das Erscheinungsbild des Diagramms mit Diagrammeinstellungen anpassen (Eigenschaftsfenster ganz rechts unten):
Man kann hier unter anderem die Isoplethen für verschiedene Auskeimungszeiträume einblenden und so beispielsweise folgendes Isoplethendiagramm konfigurieren:
Die Einstellungen werden nachfolgend im Detail beschrieben:
11.1.1. Startzeit/Endzeit
Es werden nur die Werte im angegebenen Zeitraum betrachtet. Für die Bewertung ist es meist sinnvoll, das erste Jahr auszublenden, damit Einschwingvorgänge das Ergebnis nicht verfälschen.
|
Wenn man mit der Maus kurz über den Eingabefeldern für Start-/Endzeitpunkt bleibt, wird im zugehörigen Tooltip der mögliche Bereich angezeigt. |
11.1.2. Mittelung
Meist werden Stundenwerte (Momentanwerte am Stundenende) für die Berechnung verwendet und auch angezeigt.
Für eine Schimmelbildung müssen die verwendeten Grenzwerte für längere Zeit überschritten werden. Entsprechend sind auch die Auskeimungs-Isoplethen für bestimmte Zeiträume definiert, bspw. 1 Tag oder 2 Tage. Für eine visuelle Bewertung der Berechnungsergebnisse empfielt es sich daher, die Einzelwerte in einem ähnlichen Zeitinterval zu mitteln, z.B. durch Verwendung von 24 h als Mittelungsinterval (Eingabe von 24h im Feld Mittelung). Bei längeren Auskeimungsintervallen sollte man den Mittelungszeitraum entsprechend vergrößern.
|
Das Mittelungsinterval hat nur eine Auswirkung auf die Diagrammanzeigen, nicht jedoch auf die numerische Berechnung der Überschreitungshäufigkeiten/Überschreitungszeiträume. |
11.1.3. Zeige Ergebnis im Diagramm
Wenn der Haken in diesem Feld gesetzt ist, werden die Überschreitungszeiträume für jede gewählte Isoplethe in der Legende mit angezeigt.
11.1.4. Isoplethen
In diesem Bereich können die verschiedenen Isoplethen gewählt werden. Hierbei wird nach Nährstoffangebot an der Oberfläche sowie Zeitdauer des möglichen Wachstums unterschieden. Es gibt Isoplethen für einen Tag, zwei Tage, 4 Tage, 8 Tage und 16 Tage. Dies bedeutet, dass die Bedingungen an der Oberfläche für den genannten Zeitraum oberhalb der Grenzlinie (Isoplethe) liegen müssen, damit Schimmel auftreten kann. Weiterhin gibt es noch eine Linie für die Auskeimungsgrenze. Diese beschreibt die untere Grenze für die Auskeimung von Schimmelsporen. Unterhalb dieser Linie ist das Risiko für Schimmelbildung bei Null. Im Bild oben sind die Isoplethen für Auskeimungsgrenze, einen Tag und zwei Tage gewählt.
11.1.5. Ergebnisexport nach csv
Diese Schaltfläche unten im Dialog exportiert eine Tabelle mit den Überschreitungshäufigkeiten für alle Isoplethen als csv-Datensatz in die Zwischenablage. Von dort kann sie z. B. in ein Textverarbeitungsprogramm oder Tabellenkalkulation (Excel/LibreOffice-Calc/etc.) übernommen werden:

Es werden zwei Spalten dargestellt:
| Gesamtzeit |
Wieviele Tage waren die Werte im gesamten gewählten Zeitraum über der Grenzlinie. Dabei wird eine Überschreitung nur gerechnet, wenn die Zeit jeder einzelnen Überschreitung den Wert der Isoplethe übersteigt. |
| Maximale Zeitdauer |
Dies ist die längste Zeitdauer in Stunden für Überschreitungen bei dieser Isoplethe. Dieser Wert kann auch kürzer als die Zeitspanne der entsprechenden Isoplethe sein. Dann wäre dort die Überschreitungszeit Null. |
11.2. VTT Schimmelmodell
Das VTT Schimmelmodell ist ein mathematisches Modell zur dynamischen Berechnung des Schimmelwachstums aus Temperatur und relativer Luftfeuchte einer Oberfläche. Es wurde von Hannu Viitanen vom VTT in Finnland entwickelt. Nähere Informationen finden Sie z. B. in:
Hukka A.; Viitanen H.: A mathematical model of mould growth on wooden material. Wood Science and Technology 33(6). 1999, S. 475-485.
Das Ergebnis dieses Modells ist ein Zeitverlauf eines Schimmelindexes:
| Schimmelindex | Wachstum | Beschreibung |
|---|---|---|
0 |
kein Wachstum |
Sporen nicht aktiv |
1 |
mikroskopisch sichtbares, geringes Wachstum |
Auskeimung |
2 |
mikroskopisch sichtbar, <10% Bedeckung |
- |
3 |
visuell sichtbar, 10-30% Bedeckung |
Neue Sporen werden produziert |
4 |
visuell sichtbar, 30-70% Bedeckung |
Mittleres Wachstum |
5 |
visuell sichtbar, >70% Bedeckung |
Starkes Wachstum |
6 |
Bedeckung 100% |
Sehr starker und dichter Bewuchs |
Ein Schimmelauswertungsdiagramm für das VTT Schimmelmodell wird genau wie beim Isoplethenmodell erstellt. Das erstellte Diagramm kann mit den dazugehörigen Diagrammeigenschaften (ganz unten rechts in der Eigenschaftspalette) angepasst werden.
Im Optionsdialog können drei Parameter eingestellt werden.
| Typ des Materials |
|
| Typ der Oberfläche |
|
| Typ der Schimmelrückbildung |
|
11.3. WTA Holzzerstörungsmodell
Dieses Modell dient dem Nachweis des Holzabbaus durch holzzerstörende Pilze. Es ist beschrieben im
WTA Merkblatt 6.8 (2016) Kap. 6.4.1.
Es gilt für Massivholz (einschließlich Konstruktionsvollholz, verklebte und verdübelte Holzprodukte, Brettschichtholz u.ä.). Hier wird eine Art lineare Isoplethe für den Temperaturbereich 0°C bis 30°C verwendet. Ein Risiko für Holzzerstörung gilt als gegeben, wenn die Oberflächenwerte als eintägiger Mittelwert über dieser Linie liegen. Die Mittelwertbildung erfolgt im Modell.
Weiteres hierzu ist in folgender Literatur zu finden:
Kehl, D.: Feuchtetechnische Bemessung von Holzkonstruktionen nach WTA - Hygrothermische Auswertung der anderen Art. In: HOLZBAU - die neue quadriga, Heft 06-2013, Kastner Verlag, Wolnzach 2013.
Auf dieses Modell wird ebenfalls in der DIN 4108-3 von 2018 verwiesen (Kap.D.7.4 S. 72).
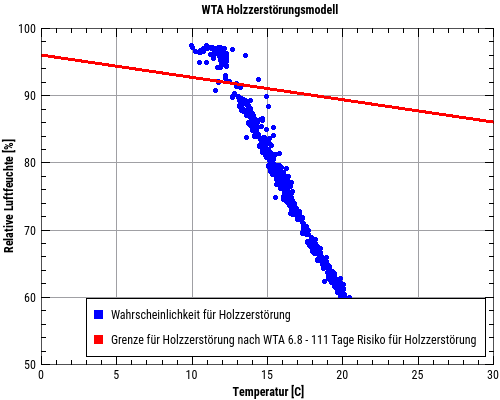
Als Parameter kann hier lediglich der Bewertungszeitraum angegeben werden. Dies erfolgt analog zum Isoplethenmodell. Genau wie dort kann ein Überschreitungszeitraum in Tagen in der Legende dargestellt werden. Ebenfalls ist ein Export einer Tabelle als csv möglich (siehe Ergebnisexport nach csv).
11.4. VTT Holzzerstörungsmodell
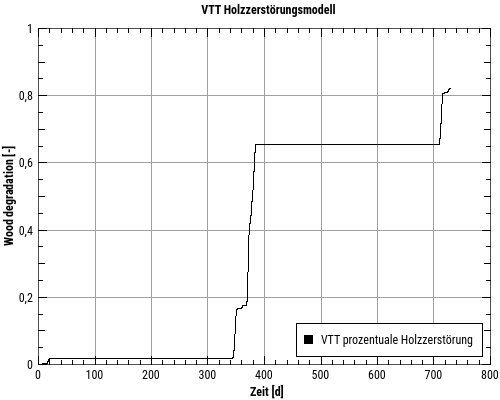
11.5. Algenwachstum auf einer Oberfläche aus Mauerziegel
Das vorliegende Modell beschreibt die zunehmende Bedeckung einer äußeren Oberfläche für Ziegelmauerwerk mit Algen. Eine endgültige Dokumentation dieses Modells steht noch aus. Eine erste Beschreibung ist hier zu finden:
Quagliarini, E.; Gianangeli, A.; D’Orazio, M.(u. a.): Effect of temperature and relative humidity on algae biofouling on different fired brick surfaces. Constr. Build. Mater. 199. 2019, S. 396–405., doi:10.1016/J.CONBUILDMAT.2018.12.023.
Als Eingangsgrößen sind auch hier die Temperatur und die relative Luftfeuchte an einer äußeren Oberfläche zu verwenden. Stundenwerte sind hier zu bevorzugen. Im Diagramm kann man die Bedeckung der Oberfläche mit Algen ablesen, die sich mit der Zeit dem für das verwendete Material maximalen Wert annähert.
Als Parameter gehen die Porosität des Materials an der Oberfläche und die Rauhigkeit der Oberfläche ein. Die Porosität kann man aus den Materialeigenschaften des verwendeten Simulationsmodells entnehmen. Die Parameter werden im Optionsdialog rechts unten in der Diagrammeigenschaftspalette eingegeben.
Die Parameter haben dabei folgende Grenzen:
| Porosität |
0,19m³/m³ bis 0,44m³/m³ |
| Rauhigkeit |
2,95µm bis 7,6µm |
12. Diagrammexport
Eine der Stärken vom PostProc 2 ist der druckreife Diagrammexport, wobei je nach Zielanwendung präzise Größen- und Skalierungseinstellungen gemacht werden können.
Diagramme können wahlweise als:
-
Bitmap-Grafiken (Pixel/Rasterbasiert, ideal für Webseiten), und
-
Vektor-Grafiken (pdf, svg, emf) für gedruckte Publikationen
erstellt werden.
Diagramme können auf zwei Arten exportiert werden:
-
schnelle direkte Kopie in die Zwischenablage mit Standardeinstellungen, und
-
durch Verwendung des Export-Dialogs mit sehr detaillierten Exporteinstellungen.
Zum Export eines Diagramms muss das jeweilige Diagrammfenster markiert sein.
12.1. Schnelle Kopie in die Zwischenablage
Bei Ausführung des Menübefehls: Chart - Kopiere aktuelles Diagramm in die Zwischenablage wird unter Windows automatisch eine EMF-Vektor-Datei kopiert und unter Linux/MacOS ein Bitmap-Bild (wie bei einem Screenshot). Hierbei wird das Diagramm mit der aktuellen Größe exportiert.
So wird beispielsweise das so auf dem Bildschirm angezeigtes Diagramm:
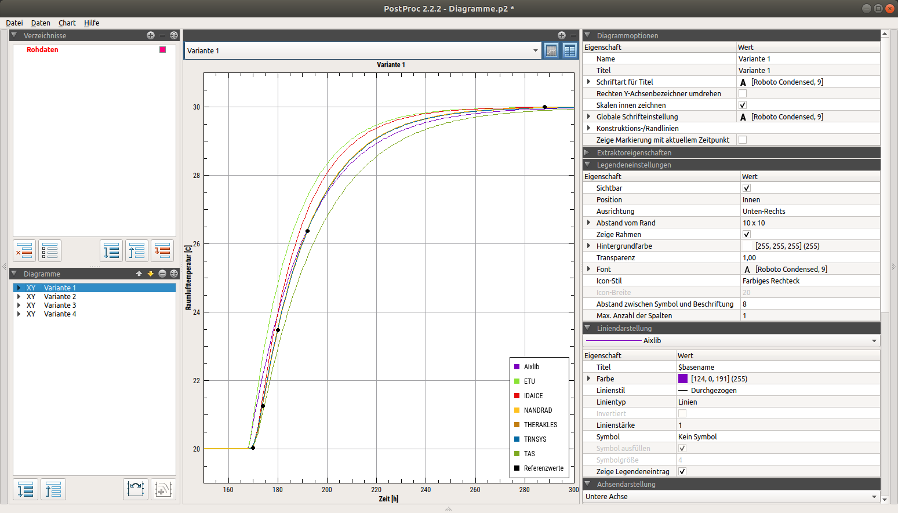
beim Kopie-in-die-Zwischenablage-Befehl als nahezu 1-zu-1 Abbild exportiert:
12.2. Verwendung des Exportdialogs/Diagrammlayout für Publikationen
Häufig sind jedoch detaillierte Exporteinstellungen hinsichtlich der Zielgröße, Auflösung etc. notwendig. Diese können im Diagramm-Export-Dialog ausgewählt werden. Den Export-Dialog kann man über den Menübefehl: Chart - Aktuelles Diagramm exportieren oder über den Kurzbefehl Strg+E öffnen.
Der Diagramm-Export unterscheidet sich grundlegend zwischen pixelbasierten Bitmap-Bildern und Vektorgraphikbildern. Im Dialog kann über die Auswahl der Registerkarte Bitmap oder Vektorgraphik zunächst diese grundlegende Einstellung getroffen werden.
Nach Auswahl der Format-spezifischen Einstellungen (siehe folgende Abschnitte) kann das Diagramm entweder als Datei gespeichert oder in die Zwischenablage kopiert werden.
12.2.1. Auswahl des Diagrammziels

Zum Speichern in einer Daten muss der Datenpfad einschließlich Erweiterung in die Dateinamenszeile (1) eingetragen werden. Dazu kann auch die Auswahlschalffläche (2) verwendet werden. Je nach eingegebener Dateierweiterung (Kleinschreibung beachten!), wird das Zielformat bestimmt.
Unterstützt werden derzeit:
Vektorgraphikformate:
-
pdf- PDF-Datei -
emf- (nur Windows) - Enhanced MetaFile Bilddatei -
svg- SVG Vektorgraphikdatei
Bitmapgraphikformate:
-
png- PNG-Bild -
jpg- JPG-Bild -
bmp- BMP-Bild
Das eigentliche Bild wird durch die Schaltfläche (3) In Datei exportieren geschrieben.
|
Beim Speichern der Datei wird eine eventuell existierende Datei ohne weitere Bestätigung überschrieben. Wenn man allerdings den Dateinamen-Auswahldialog verwendet, wird bei Wahl einer existierenden Datei nachgefragt, ob diese Datei überschrieben werden soll. Dies führt jedoch noch nicht sofort zum Überschreiben der Datei, sondern erst, wenn die In Datei exportieren Schaltfläche gedrückt wird. |
Alternativ kann man das Bild auch in die Zwischenablage kopieren (Schaltfläche (4) In die Zwischenablage kopieren).
12.3. Vektorgraphik-Export
Vektorgraphiken haben den Vorteil, dass bei Skalierung des Bildes die Qualität erhalten bleibt. Damit ist dies auch das empfohlene Format für Diagramme, die gedruckt werden sollen. Man kann dann z.B. eine PDF-Datei erstellen, oder die Grafik als EMF-Datei (Windows) oder SVG-Datei in andere Dokumente einbinden.
Grundlegend ist zu beachten, dass die Formateinstellungen der Linien und Titel beim Export exakt berücksichtigt werden. D.h., wenn man als Schriftgröße 10pt eingestellt hat, so wird beim Diagrammexport auch der Text auch mit 10pt geschrieben - egal ob man ein 10x10cm oder 150x150cm Diagramm exportiert.
|
Das Erscheinungsbild eines exportierten Diagramms weicht je nach Einstellung von der Bildschirmdarstellung ab, weswegen eine Voransicht angezeigt wird. |
Für Publikationen ist es häufig wichtig, Schriftgrößen in Abbildungen in exakt geforderter Größe anzugeben, beisielsweise Arial 9pt. PostProc 2 unterstützt dies, indem man in den Diagrammkonfigurationen individuell Größen für Schriftfonts und Linienstärken einstellen kann, und diese dann exakt so beim Export benutzt werden. Fügt man dann ein z.B. 12x7cm Diagramm mit exakt dieser Größe in ein anderes Dokument ein, so haben beim anschließenden Druck die Schriftzeichen genau die geforderte Größe.
Beim Export des Diagramms wird das Diagramm mit der angegebenen Größe neu gezeichnet, wobei sich natürlich die Propertionen und Achsenskalierungen ändern können. Deshalb wird eine Voransicht des Diagramms angezeigt.
|
Beim Vektorexport werden zudem noch die Linienstärken angepasst. Wenn man auf einem FullHD-Bildschirm mit 1920x1080 er Auflösung eine Linie mit 1px Breite zeichnet und diese auch gut erkennbar ist, so ist erscheint eine entsprechend skalierte 1px-Linie beim Export in ein druckfähiges Diagramm als sehr dick (bspw. 0,8 mm dick). Deshalb werden Linienstärken beim Vektor-Export halbiert. |
Wichtigste Einstellung beim Vektorexport ist die Zielgröße. Sofern Behalte Seitenverhältnis bei aktiviert ist, wird bei der Änderung der Breite oder Höhe die jeweils andere Größe automatisch proportional angepasst. Auf früher gewählte Seitenverhältnisse kann über das Drop-down-Menü Zuletzt verwendete Größen zurückgegriffen werden.
Neben der Einstellung der Zielgröße des Diagramms (in mm), gibt es noch zwei weitere Optionen.
12.3.1. Datenreduktion für den Export verwenden
Beim Export von Liniendiagrammen mit sehr vielen Datenpunkten als Vektorgrafik kann ein zusätzlicher Datenreduktionsalgorithmus eingeschaltet werden. Dabei werden alle Punkte entfernt, welche näherungsweise auf der Verbindungslinie zwischen den Nachbarpunkten liegen und somit keinen Mehrwert im Diagramm bringen. Es kommt hierbei der Douglas-Peucker-Algorithmus zum Einsatz.
Die Datenreduktion kann helfen, die Größe der erstellten PDF-/SVG-/EMF-Dateien ohne sichtbaren Qualitätsverlust drastisch zu verkleinern, Beispielsweise bei einer Liniengrafik mit 180000 Punkten von 18 Mb auf 0.2 Mb.
Es wird beim Datenexport lediglich die Segmentzahl der Linie (Polyline) reduziert. Symbole werden, falls sichtbar, für jeden Punkt gezeichnet. Die Operation führt deshalb zu einer optisch gleichwertigen Diagrammdarstellung.
|
Beim Kopieren einer Vektorgrafik in die Zwischenablage über den Menübefehl Kopiere aktuelles Diagramm in die Zwischenablage wird immer eine Datenreduktion angewendet. |
12.3.2. Diagrammhintergrund zeichnen (keine Transparenz)
Standardmäßig ist diese Option eingeschaltet und unter das Diagramm wird eine weiße, einfarbige Fläche gezeichnet. Dies ist u. a. für den PDF-A Export notwendig, da hier keine transparenten Vektorzeichnungen erlaubt sind.
Möchte man jedoch explizit ein transparentes Diagramm erhalten, um es beispielsweise in eine Präsentation mit anderem Farbhintergrund einzufügen, dann kann man diese Option ausschalten.
12.4. Export als pixelbasierte Grafik/Rasterbild
Diagramme werden üblicherweise nur als Rasterbilder exportiert, wenn sie z.B. in Webseiten oder anderen rasterbasierten Darstellungsformen benötigt werden. Da hierbei häufig eine präzise Darstellung gewünscht ist, gibt es eine exakte Voransicht des exportierten Bildes.
Bei Auflösungen, die größer als das Exportdialogfenster sind, werden bei Originalgrößen-Voransicht Laufbalken angezeigt. Man kann auch die proportionale Voransicht wählen.
Da Rastergrafiken auch für den Druck verwendet werden können, ist die Größeneinstellung einmal über die Pixelabmessung und einmal über Größe und Auflösung möglich.
12.5. Tipps und Tricks für die Erstellung von Diagrammen für Publikationen/Druck
Diagramme für den Druck (für Publikationen, Bücher etc.) sollten stets als Vektorgrafiken exportiert werden.
Folgende Vorgehensweise ist empfehlenswert:
-
Konfiguration des Diagramms in der Bildschirmansicht
-
Festlegen der Schriftart und Größe, kann zentral für das gesamte Diagramm via globalen Diagrammoptionen erfolgen
-
Öffnen des Exportdialogs
-
Festlegen der Diagrammgröße, z. B. 16 cm Breite bei normalem A4-Papier oder z. B. 8 cm bei zweispaltigem Druck. Analog die Höhe auswählen.
-
Voransicht betrachten - diese zeigt die Proportionen des zu exportierenden Diagramms, welche durchaus von den Bildschirmproportionen abweichen können. Gegebenenfalls Exportdialogfenster schließen und Schriftarten und Linienstärken anpassen.
-
Diagramm exportieren und beim Einfügen in Zieldokument die Größe entsprechend festlegen.
12.5.1. Einheitliche Ausrichtung mehrerer Diagramme im Dokument
Sollten mehrere Diagramme in einem Dokument verwendet werden, so empfiehlt sich die Verwendung der gleichen Schriftart und Größe für alle Diagramme. Auch sollten die Exportgrößen gleich sein.
Zusätzlich kann mit der Achseneigenschaft Titelabstand ein einheitlicher Abstand zwischen Achse und Diagrammtitel (und damit auch Diagrammrand) eingestellt werden. Dies ist u. a. sinnvoll, wenn man zwei Diagramme mit unterschiedlichen Skalengrößenordnungen untereinander darstellt.
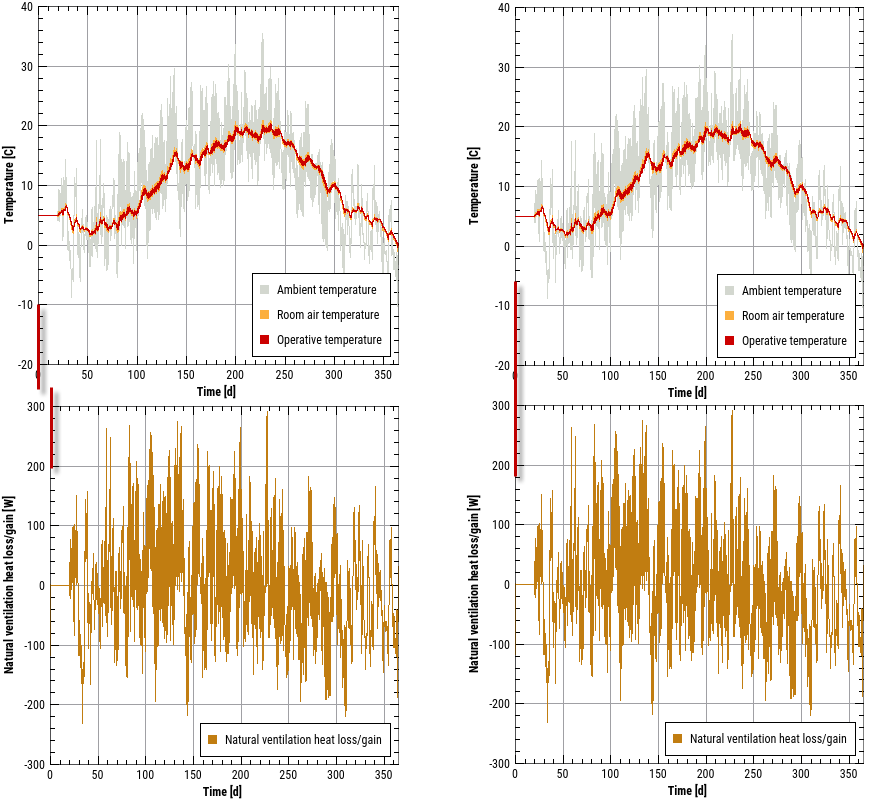
12.6. Automatisierter Diagrammexport
Es besteht auch die Möglichkeit, den Diagrammexport automatisch über einen Kommandozeilenbefehl auszuführen, siehe Abschnitt Automatisierte Diagrammerstellung mittels Kommandozeilenbefehl.
13. Referenz
13.1. Kurzbefehle
Viele Funktionen im Postprozessing lassen sich über einen Doppelklick oder einen Tastaturkurzbefehl ausführen:
| Kurzbefehl/Aktion | Funktion |
|---|---|
Doppelklick (auf Datensatz in Datenmanagertabelle) |
Erstellen eines Diagramms für den aktuell gewählten Datensatz mit Standardoptionen |
Strg+N |
Neue leere Sitzung erstellen |
Strg+O |
Sitzung öffnen |
Strg+S |
Sitzung speichern |
Strg+A |
Alles auswählen, in Listen und Tabellen, z. B. in der Tabellenansicht der Diagrammdaten |
Strg+E |
Export des aktuell gewählten Diagramms, Diagramm muss Fokus haben (mit Maus darauf klicken) |
F5 / Strg+R |
Daten aktualisieren (Reload) |
F2 |
Öffne aktuelle Sitzungsdatei in Texteditor |
Strg+1 |
Aktuelles Diagramm horizontal teilen (2 Diagramme untereinander) |
Strg+2 |
Aktuelles Diagramm vertikal teilen (2 Diagramme nebeneinander) |
Strg+0 |
Diagrammfenster schließen/Teilung aufheben |
F11 |
Vollbildmodus ein/aus (im Vollbildmodus werden alle Paneele weggeklappt) |
13.2. Kommandozeilenreferenz
Die folgenden Kommandozeilenargumente werden unterstützt:
Syntax:
> PostProcApp [<Optionen>] [<Sitzungsdatei>]
Mögliche Optionen werden mit dem Argument --help angezeigt:
Syntax: PostProcApp [flags] [options] arg1 arg2 ...
Flags:
--help Prints the help page.
--man-page Prints the man page (source version) to std output.
--cmd-line Prints the command line as it was understood by the command
line parser.
--options-left Prints all options that are unknown to the command line
parser.
--no-splash Disables splash screen.
Options:
--lang=<en;de;it;...>
Specify the program language using a 2 character language
ID.
--generate-chart=<n:bxh:fn>
Export chart #n, with dimensions 'width x height' and
filename fn like 'diagram1.pdf'.
--generate-charts=<exportSpecsFile>
Exports several charts using export specs from given file.Wird eine Sitzungsdatei übergeben, stellt das PostProzessing diese Sitzung bei Programmstart wieder her. Unter Windows/Linux ist die Dateierweiterung p2 mit _ PostProc 2_ verknüpft, sodass bei Doppelklick auf eine Sitzungsdatei das PostProc mit dieser Sitzung startet.
Die wichtigsten optionalen Argumente sind:
--no splash
|
Deaktiviert den Splashscreen |
--lang=<Sprach-id>
|
Gibt an, mit welcher Programmsprache das Programm gestartet werden soll. Mögliche Sprach-IDs: de, en, it |
--generate-chart
|
Öffnet PostProc 2, liest die übergebene Sitzungsdatei, generiert ein Diagramm entsprechend der Argumentoptionen und schließt das Programm wieder |
--generate-charts
|
Im Prinzip wie |
13.2.1. Automatisierte Diagrammerstellung mittels Kommandozeilenbefehl
Die oben erwähnten Kommandozeilenargumente --generate-chart und --generate-charts können dazu benutzt werden, automatisiert Diagramme zu erstellen. In Verbindung mit einer skriptgestützten Erstellung einer Sitzungsdatei kann man so komplett automatisch Diagramme generieren.
Das Argument --generate-chart dient dazu, ein einzelnes Diagramm zu exportieren. Beispielsweise führt der Befehl:
> PostProcApp --generate-chart=2:160x100:diagram1.pdf diagramme.p2folgende Arbeitsschritte aus:
-
Starten von PostProc 2
-
Öffnen der Sitzungsdatei
diagramme.p2 -
Wechsel zum Diagramm #2
-
Erstellen der PDF-Datei
diagram1.pdfmit Auflösung 160x100 mm des Diagramms #2 -
Schließen des Programms und Rückkehr zur Kommandozeile
Möchte man mehrere Diagramme der gleichen Sitzungsdatei erstellen, so kann man das prinzipiell über den mehrfachen Start der Anwendung mit dem --generate-chart Argument machen. Allerdings dauert dies bei größeren Sitzungsdateien mitunter sehr lange. Man kann daher stattdessen auch eine Textdatei mit jeweils einer Export-Definition je Zeile erstellen. Ein Beispiel dafür wäre:
exportSpec.txt für eine Diagrammexport-Spezifikationsdatei1:160x120:../Bericht/Diagramme/Variante1.pdf
2:160x120:../Bericht/Diagramme/Variante2.pdf
3:160x120:../Bericht/Diagramme/Variante3.pdf
4:160x120:../Bericht/Diagramme/Variante4.pdfJede Zeile enthält die gleichen Parameter, wie man sie dem Argument --generate-chart übergeben würde. Nun startet man das PostProcessing mit:
> PostProcApp --generate-charts=exportSpec.txt diagramme.p2wobei das Argument --generate-charts den absoluten oder relativen Pfad zur Spezifikationsdatei definiert.
13.3. Einheitensystem und Einheitenliste
PostProc 2 hat ein eingebautes Einheitensystem, welches für die Einheitenumrechnung verwendet wird. Dadurch können z.B. Datenreihen mit ineinander konvertierbaren Einheiten sinnvoll in einem Diagramm dargestellt werden.
Eine Datenreihe enthält Labormessdaten, welche in Minutenschritten protokolliert werden: Werteeinheit=g (Gramm), Zeiteinheit=min (Minute)
Wenn man aus einer solchen Datenreihe nun ein 2D-Diagramm erstellt, wird die X-Achse die Einheit min erhalten und die Y-Achse die Einheit g.
Nun fügt man eine weitere Datenreihe (aus einer Simulation) hinzu, wobei hier die Standard-SI-Einheit kg als Werteinheit verwendet wird, und als Zeiteinheit s. PostProc 2 versucht nun mittels der Einheitentabelle den Umrechnungsfaktor von kg zu g zu bestimmen, und gleichermaßen für s zu min. Dann werden die Werte der Datenreihe entsprechend umgerechnet und passend im Diagramm angezeigt.
Das Einheitensystem basiert auf direkten 1-zu-1 Umrechnungen. Meist sind das Skalierungen, und im Fall von C nach K eine Werteverschiebung. Spezielle Einheitenumrechnungen wie sqrt(s) nach s sind direkt integriert.
Korrelationen zwischen Einheiten, also z.B. das m2/s durch Berechnung von m * m/s entstehen, sind nicht integriert, da derartige Berechnungen im PostProc 2 nicht durchgeführt werden.
13.3.1. Einheitenliste
In der folgenden Tabelle sind alle in PostProc 2 unterstützten Einheiten aufgeführt, d.h. Einheiten, welche in Datendateien als Werte- und Zeiteinheiten verwendet werden können.
| Basis-Einheit | Konvertierbare Einheiten |
|---|---|
- |
|
--- |
%, 1 |
---/d |
%/d |
1/K |
|
1/logcm |
|
1/m |
1/cm |
1/Pa |
|
1/s |
1/min, 1/h |
J |
kJ, MJ, MWh, kWh, Wh |
J/K |
kJ/K |
J/kg |
kJ/kg |
J/kgK |
kJ/kgK, Ws/kgK, J/gK, Ws/gK |
J/m2 |
kJ/m2, MJ/m2, GJ/m2, J/dm2, J/cm2, kWh/m2 |
J/m2s |
W/m2, kW/m2, MW/m2, W/dm2, W/cm2 |
J/m3 |
Ws/m3, kJ/m3, MJ/m3, GJ/m3, J/dm3, J/cm3, kWh/m3 |
J/m3K |
kJ/m3K |
J/m3s |
kJ/m3s, MJ/m3s, J/dm3s, J/cm3s, J/m3h, W/m3, kW/m3, MW/m3, W/dm3, W/cm3, W/mm3 |
J/mol |
kJ/mol |
J/s |
J/h, J/d, kJ/d, W, kW, MW, Nm/s |
K |
C |
K/m |
|
K/Pa |
|
kg |
g, mg |
kg/kg |
g/kg, mg/kg |
kg/m |
g/m, g/mm, kg/mm |
kg/m2 |
kg/dm2, g/dm2, g/cm2, mg/m2 |
kg/m2s |
g/m2s, g/m2h, g/m2d, kg/m2h, mg/m2s, µg/m2s, mg/m2h, µg/m2h |
kg/m2s05 |
kg/m2h05 |
kg/m3 |
kg/dm3, g/dm3, g/cm3, g/m3, mg/m3, µg/m3, log(kg/m3), log(g/m3), log(mg/m3), log(µg/m3) |
kg/m3s |
g/m3s, g/m3h, kg/m3h, mg/m3s, µg/m3s, mg/m3h, µg/m3h |
kg/m3sK |
g/m3sK, g/m3hK, kg/m3hK, mg/m3sK, µg/m3sK, mg/m3hK, µg/m3hK |
kg/mol |
g/mol |
kg/ms |
|
kg/s |
kg/h, kg/d, g/d, g/a, mg/s, µg/s |
kWh/a |
|
kWh/m2a |
|
l/m2s |
l/m2h, l/m2d, mm/d, mm/h |
l/m3s |
l/m3h |
logcm |
|
logm |
|
logPa |
|
Lux |
kLux |
m |
mm, cm, dm |
m/s |
cm/s, cm/h, cm/d |
m/s2 |
|
m2 |
mm2, cm2, dm2 |
m2/kg |
|
m2/m3 |
|
m2/s |
cm2/s, m2/h, cm2/h |
m2K/W |
|
m2s/kg |
|
m3 |
mm3, cm3, dm3 |
m3/m2s |
m3/m2h, dm3/m2s, dm3/m2h |
m3/m2sPa |
m3/m2hPa |
m3/m3 |
Vol% |
m3/m3d |
Vol%/d |
m3/s |
m3/h, dm3/s, dm3/h |
m3m/m3m |
m3mm/m3m |
mm/m |
|
mol |
mmol |
mol/kg |
mol/g |
mol/m3 |
mol/ltr, mol/dm3, mol/cm3 |
Pa |
hPa, kPa, Bar, PSI, Torr |
Pa/m |
kPa/m |
Person/m2 |
|
Rad |
Deg |
s |
min, h, d, a, sqrt(s), sqrt(h), ms |
s/m |
kg/m2sPa |
s/s |
min/s, h/s, d/s, a/s |
s2/m2 |
|
W/K |
|
W/m2K |
|
W/m2K2 |
|
W/m2s |
W/m2h, kW/m2s, MW/m2s, W/dm2s, W/cm2s |
W/mK |
kW/mK |
W/mK2 |
|
W/Person |
kW/Person |
undefined |
Spezielle Bedeutung haben die Enheiten undefined und '-'. Letztere wird für einheitenlose Variablen verwendet. PostProc 2 gibt die Einheit '-' allen Daten aus Eingabedateien ohne angegebene Einheit.
|
Die Einheit |
13.4. Sitzungsdateiformat
Die Sitzungsdatei ist wie folgt strukturiert:
<?xml version="1.0" encoding="UTF-8" ?>
<PostProc version="2.2.1">
<!--List of all directories-->
<Directories>
...
</Directories>
<!--All mappers.-->
<Mappers>
...
</Mappers>
<!--Split window state.-->
<Splitting>
...
</Splitting>
</PostProc>13.4.1. XML-Element <Directories>
Die Information über die in die Sitzung importierten Verzeichnisse und welche davon gerade markiert sind, d.h. Inhalt und Zustand des Verzeichnisbaums wird in der Sitzungsdatei im Abschnitt <Directories> gespeichert.
<!--List of all directories-->
<Directories>
<Directory>
<Path>1DGeometry</Path>
<SubDir Color="#550000" Checked="1">DirectSimData</SubDir>
<SubDir Color="#ffaaff" Checked="0">FluxFieldTest/horizontal_flux_field</SubDir>
<SubDir Color="#c66300" Checked="0">TimeCoordinateValuePlot/TimeCoordinateValuePlot</SubDir>
<SubDir Color="#005500" Checked="0">TimeCoordinateValuePlot/TimeCoordinateValuePlotYDir</SubDir>
<SubDir Color="#ffee00" Checked="1">TimeCoordinateValuePlot/TimeCoordinateValuePlot_withGap</SubDir>
<SubDir Color="#ff5500" Checked="0">xtime_plot/climate</SubDir>
<SubDir Color="#aa55ff" Checked="0">xtime_plot/xtime_plot_nogaps</SubDir>
<SubDir Color="#aaaa00" Checked="0">xtime_plot/xtime_plot_nogaps.results</SubDir>
<ExpandedSubDir>TimeCoordinateValuePlot</ExpandedSubDir>
<ExpandedSubDir>.</ExpandedSubDir>
<ExpandedSubDir>xtime_plot</ExpandedSubDir>
</Directory>
<Directory>
<Path>/home/ghorwin/svn/PostProcApp_trunk/data/Examples/2DGeometry</Path>
<SubDir Color="#ffee00" Checked="0">LShape</SubDir>
<ExpandedSubDir>.</ExpandedSubDir>
</Directory>
</Directories>Jedes hinzugefügte Verzeichnis erscheint in einem eigenen <Directory> Element, wobei der Pfad entweder als relativer oder absoluter Pfad angegeben wird:
-
als relativer Pfad zum Verzeichnis der Sitzungsdatei, wenn sich das ausgewählte Verzeichnis unterhalb dieses Sitzungsverzeichnisses befindet,
-
als absolute Pfad, wenn sich das ausgewählte Verzeichnis woanders befindet (übergeordnetes Verzeichnis, andere Verzeichnishierarchie, anderes Laufwerk, etc.)
Im Beispiel oben ist die Sitzungsdatei als /home/ghorwin/Simulationen/1DSim.p2 gespeichert, und damit liegt das erste importierte Verzeichnis 1DGeometry im Pfad /home/ghorwin/Simulationen/1DGeometry. Die in den xml-tags <SubDir> angegebenen Pfade sind relativ zu diesem Verzeichnis zu verstehen. Das zweite importierte Verzeichnis ist mit absolutem Pfad angegeben, da dieses Verzeichnis außerhalb der Sitzungsverzeichnisstruktur (beginnend mit /home/ghorwin/Simulationen) gespeichert ist.
|
Falls man eine gesamte Verzeichnistruktur mit Sitzungsdatei und Datensätzen kopieren/verschieben möchte, oder in einem Versionskontrollsystem verwenden will, sollte man die Sitzungsdatei im obersten Verzeichnis ablegen. Dadurch sind alle Verzeichnisse relativ zum Sitzungsdateipfad angelegt und die Sitzungsdatei kann auf verschiedenen Rechnern ohne weitere Pfadanpassungen direkt verwendet werden. |
Die Attribute von <SubDir> sind selbsterklärend. Die optionalen <ExpandedSubDir>-tags werden verwendet, um den Ausklapp-Zustand des Verzeichnisbaums abzulegen.
13.4.2. XML-Element <Mappers>
Dieses Element enthält letztlich eine Liste von <Mapper> Elementen, wobei jedes für ein Diagramm steht.
13.4.3. XML-Elemente <Mapper>
Ein <Mapper> XML-Tag enthält alle Daten für ein Diagramm und die darin dargestellten Datenreihen. Es sind zwei XML-Tags enthalten:
<Mapper name="Surface temperature">
<Extractors>
<!-- Definition, wie Daten aus Quelldateien extrahiert werden -->
</Extractors>
<ChartModel chartType="2D">
<!-- Definition, wie Daten und Diagramm darzustellen ist -->
</ChartModel>
</Mapper>Auch in der Datenablage gibt es eine Trennung zwischen der Beschreibung, wie die Daten aus Quelldateien extrahiert werden und der Definition, wie die Daten darzustellen sind.
Je Datenreihe im Diagramm gibt es ein Extractor-Tag innerhalb des übergeordneten Extractors-Tags.
XML-Elemente <Extractor>
Jedes Extractor-Element definiert eine Datenreihe. Nachfolgend ist ein Beispiel für einen 2D Datensatz gezeigt:
<Extractor>
<DataIOFileName>1DGeometry/DirectSimData/surface_temperature.d6o</DataIOFileName>
<CutType>NoCut</CutType>
<DataFormat>DF_2D</DataFormat>
</Extractor>Und hier ist ein Beispiel für eine 2D Datenreihe, extrahiert als Zeitschnitt aus einem 3D Datensatz:
<Extractor>
<DataIOFileName>1DGeometry/DirectSimData/temperature_field.d6o</DataIOFileName>
<CutType>TimeCut</CutType>
<DataFormat>DF_3D</DataFormat>
<CutIndexT locked="no">218</CutIndexT>
</Extractor>|
Die Pfadangabe zur Quelldatei ist relativ zum Sitzungsdateipfad, falls die Datendatei unterhalb dieser Verzeichnisstruktur liegt (empfehlenswert, wenn man Sitzungsdatei und Datendateien komplett weitergeben möchte). Falls die Datendatei außerhalb der Sitzungs-Datei-Verzeichnisstruktur liegt, wird ein absoluter Pfad verwendet. |
Bei 2D-Datensätzen mit mehreren Datenreihen pro Datei, wird dem Dateinamen noch die Information über die enthaltenen gruppierten Datenspalten angehängt, beispielsweise:
<Extractor>
<DataIOFileName>SimQuality_Case05/results/states.tsv?1|2|12|13|14</DataIOFileName>
<CutType>NoCut</CutType>
<DataFormat>DF_2D</DataFormat>
<DataType>T_REFERENCE</DataType>
<ColumnIndex>2</ColumnIndex>
</Extractor>Hier gibt der Suffix ?1|2|12|13|14 an, dass aus der gewählten Datei states.tsv die Datenspalten 1, 2, 12, 13 und 14 gruppiert sind (siehe auch Gruppierung von Datensätzen nach Werteeinheit).
Das XML-Tag ColumnIndex gibt an, die wievielte Datenspalte extrahiert werden soll. Dieser Index ist 0-basiert, sodass im obigen Beispiel gilt:
ColumnIndex |
Datenspalte in der Quelldatei |
|---|---|
0 |
1 |
1 |
2 |
2 |
12 |
3 |
13 |
4 |
14 |
13.4.4. XML-Element <ChartModel>
In diesem XML-Element wird die gesamte Diagrammformatierung beschrieben. Das XML-Element hat ein wichtiges Attribut chartType, welches entweder 2D, 3D oder Vector sein kann.
Bei 2D-Diagrammen enthält das ChartModel-XML-Element Serienformatbeschreibungen, bspw.:
<SeriesProperties>
<Series>
<TitleText>$quantity</TitleText>
<MarkerColor>#000000</MarkerColor>
</Series>
<Series>
<TitleText>$quantity</TitleText>
<PenColor>#ff420e</PenColor>
<MarkerColor>#ff420e</MarkerColor>
</Series>
.
.
.
</SeriesProperties>|
Es sollten immer genausoviele |
Die Formatdefinitionen sind sehr vielfältig. Es ist hilfreich, ein Diagramm in der Oberfläche entsprechend zu konfigurieren, die Sitzungsdatei abzuspeichern und dann gegebenenfalls anzupassen.
13.4.5. XML-Element <Splitting>
Dieses Element beschreibt die Diagrammteilung und Zuordnung der Diagramme zu den einzelnen Diagrammfenstern. Um beim erneuten Öffnen einer Sitzung die Diagrammteilung und Auswahl der Diagramme in den einzelnen Bereichen wiederherstellen zu können, wird eine entsprechende Datenstruktur abgelegt.
<!--Split window state.-->
<Splitting>
<Widget id="1" parent="0" viewTable="0" mapperIndex="6" size1="498" size2="497" orientation="2" />
<Widget id="2" parent="1" viewTable="0" mapperIndex="5" size1="498" size2="497" orientation="1" />
<Widget id="3" parent="1" viewTable="0" mapperIndex="0" size1="485" size2="484" orientation="2" />
<Widget id="4" parent="2" viewTable="0" mapperIndex="1" size1="485" size2="484" orientation="2" />
<FocusedWidget>1</FocusedWidget>
</Splitting>Je Diagrammfenster wird ein XML-Element <Widget> angelegt. Die darin angegebenen Größen sind als Vorschläge zu interpretieren, da die Gesamtgröße durch die aktuelle Anwendungsfenstergröße begrenzt ist, und jedes Diagramm selbst einen Mindestgröße verlangt. Das Element <FocusedWidget> gibt an, welches Diagrammfenster gerade aktiv ist (Nummer = WidgetID - 1).
Wichtig ist hierbei, die Eltern-Kind-Beziehung zu berücksichtigen. Ähnlich wie beim manuellen Aufteilen der Diagramme werden geteilte Fenster immer einem Elternfenster als Kinder zugeordnet. In der Projektdatei wird diese Information im Attribute parent abgelegt.
Ein Beispiel soll dies verdeutlichen. Eine Standardsitzung mit einem Diagrammfenster ergibt folgende Aufteilungsdatenstruktur. Die Größe ist mit 1x1 abgelegt, da die tatsächliche Größe der Fenster ja vom Anwendungsfenster abhängt.
<Splitting>
<Widget id="1" parent="0" viewTable="0" mapperIndex="0" size1="1" size2="1" orientation="2" />
<FocusedWidget>0</FocusedWidget>
</Splitting>Wird das Fenster nun vertikal geteilt, ergibt sich beispielsweise:
<Splitting>
<Widget id="1" parent="0" viewTable="0" mapperIndex="1" size1="498" size2="497" orientation="2" />
<Widget id="2" parent="1" viewTable="0" mapperIndex="1" size1="498" size2="497" orientation="1" />
<FocusedWidget>1</FocusedWidget>
</Splitting>Hierbei gibt das 2. Widget (=Diagrammfenster) an, dass es vom Elternfenster mit ID 1 (parent="1") geteilt wurde, und zwar durch vertikale Teilung (orientation="1").
Teilt man nun das linke Fenster horizontal erhält man folgende Diagrammaufteilung:
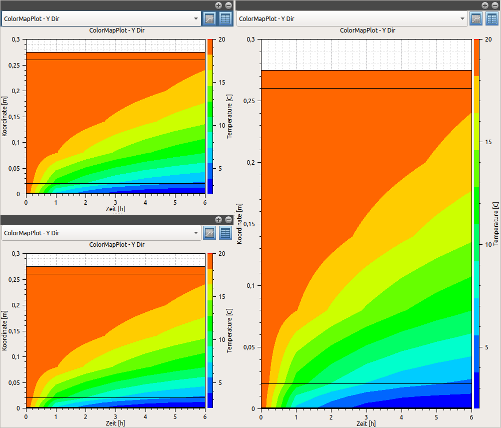
Der entsprechende Teil der Sitzungsdatei ist:
<Splitting>
<Widget id="1" parent="0" viewTable="0" mapperIndex="1" size1="466" size2="529" orientation="2" />
<Widget id="2" parent="1" viewTable="0" mapperIndex="1" size1="466" size2="529" orientation="1" />
<Widget id="3" parent="1" viewTable="0" mapperIndex="1" size1="485" size2="484" orientation="2" />
<FocusedWidget>1</FocusedWidget>
</Splitting>|
Die Größenangaben sind als Empfehlungen zu verstehen. Wird das Programmfenster in gleicher Größe geöffnet, wie zum Zeitpunkt des Speicherns der Sitzung, dann wird das Erscheinungsbild des Post-Prozessings wieder (nahezu) identisch wiederhergestellt. |